Logan Apartment Size Sofa :: Отделка ножек: Пекан / Размер: Размер квартиры — 68 дюймов в ширину
Закажите сейчас, ткань выберите позже. Узнайте больше.
Обычная цена
1672,80 долларов США (15% скидка)
Оценка 4,9 из 5
45 отзывов На основании 45 отзывов
Габаритные размеры
68 «W x 36» D x 36 «H
Глубина сиденья
23″ D
Высота сиденья
20 «H
Ширина рычага
4″ W
Высота руки
28 «H
LEG Высота
7″ h
Требуемая ширина двери
26″ w
Мы также предлагаем изготовленные на заказ пуфики, подходящие к вашему креслу, дивану или секционному дивану. Подробнее здесь. вся коллекция логан
Подробнее здесь. вся коллекция логан
- Сделано на заказ в Лос-Анджелесе, Калифорния (сделано в США)
- Экологичная конструкция
- Каркас из цельного дерева
- Чистящиеся и дышащие гипоаллергенные ткани
- Двусторонняя и откидывающаяся съемная подушка сиденья
- Легкосъемные чехлы на подушки сиденья с застежкой-молнией очистка
- Подушки сидений изготовлены из пены высокой плотности, обеспечивающей комфортную и в то же время поддерживающую посадку / без добавления антипиренов
- Пожизненная гарантия на раму и качество изготовления
Диван квартирного размера Logan — это самый простой способ добавить нотку винтажного гламура в ваше жилое пространство. Гладкие сужающиеся деревянные ножки и подушки спинки с пуговицами будут выглядеть просто потрясающе в вашей гостиной, а поскольку Apt2B думает практически обо всем, этот диван был разработан специально для жизни в квартире — так что он не слишком большой, он не слишком маленький — это просто Правильно.
Расслабьтесь на мягких подушках и поднимите ноги после рабочего дня. Наслаждайтесь выбором тканей и просмотрите более 50 различных цветов. Хотите ли вы придерживаться классического оттенка или жаждете чего-то яркого и живого, у нас это есть. На диван Logan предоставляется пожизненная гарантия.
Добавьте немного винтажного гламура в свое пространство с Logan. Гладкие деревянные ножки и тафтинговые подушки на спинке с пуговицами выводят эту современную форму на новый уровень. Идеальное украшение для вашей стильной комнаты.
Доставка: Apt2B предлагает абсолютно БЕСПЛАТНУЮ доставку каждого заказа! Наша бесплатная доставка в подъезд включает в себя размещение предметов в вашем доме или квартире. Некоторые товары могут иметь право на нашу услугу доставки в белых перчатках, которая включает размещение в комнате по выбору, сборку и удаление упаковки всего за 129 долларов США.!
Возврат: Apt2B предлагает бесплатную 100-дневную политику возврата всех заказов.
Мы искренне хотим, чтобы каждый покупатель остался доволен своей покупкой! Мы предлагаем 100 дней, чтобы испытать наши продукты лично, и отличный сервис для решения любых проблем или проблем на этом пути.Для получения дополнительной информации по вышеуказанному, пожалуйста, посетите нашу страницу доставки и возврата
- Каждое изделие мастерски изготавливается вручную на заказ в Лос-Анджелесе, Калифорния, и в настоящее время собирается за 2–4 недели до отправки вам! Заказы выполняются в порядке живой очереди, поэтому закажите сейчас, чтобы занять место в очереди.

 Мы искренне хотим, чтобы каждый покупатель остался доволен своей покупкой! Мы предлагаем 100 дней, чтобы испытать наши продукты лично, и отличный сервис для решения любых проблем или проблем на этом пути.
Мы искренне хотим, чтобы каждый покупатель остался доволен своей покупкой! Мы предлагаем 100 дней, чтобы испытать наши продукты лично, и отличный сервис для решения любых проблем или проблем на этом пути.Общие размеры
68 «W x 36» D x 36 «H
Глубина сиденья
23″ D
Высота сиденья
20 «H
Ширина рычага
4″ W
Высота ARM
28 » h
Высота ножек
7 дюймов h
Требуемая ширина двери
26 дюймов w
Мы также предлагаем изготовленные на заказ пуфики, подходящие к вашему креслу, дивану или секционному дивану.
Получите более подробную информацию здесь. Посмотреть всю коллекцию логан- Сделано на заказ в Лос-Анджелесе, Калифорния (сделано в США)
- Экологичная конструкция
- Каркас из цельного дерева
- Чистящиеся и дышащие гипоаллергенные ткани
- Двусторонняя и откидывающаяся съемная подушка сиденья
- Легкосъемные чехлы на подушки сиденья с застежкой-молнией очистка
- Подушки сидений изготовлены из пены высокой плотности, обеспечивающей комфортную и в то же время поддерживающую посадку / без добавления антипиренов
- Пожизненная гарантия на раму и качество изготовления
Диван квартирного размера Logan — это самый простой способ добавить нотку винтажного гламура в ваше жилое пространство. Гладкие сужающиеся деревянные ножки и подушки спинки с пуговицами будут выглядеть просто потрясающе в вашей гостиной, а поскольку Apt2B думает практически обо всем, этот диван был разработан специально для жизни в квартире — так что он не слишком большой, он не слишком маленький — это просто Правильно.
Расслабьтесь на мягких подушках и поднимите ноги после рабочего дня. Наслаждайтесь выбором тканей и просмотрите более 50 различных цветов. Хотите ли вы придерживаться классического оттенка или жаждете чего-то яркого и живого, у нас это есть. На диван Logan предоставляется пожизненная гарантия.Добавьте немного винтажного гламура в свое пространство с Logan. Гладкие деревянные ножки и тафтинговые подушки на спинке с пуговицами выводят эту современную форму на новый уровень. Идеальное украшение для вашей стильной комнаты.
Доставка: Apt2B предлагает абсолютно БЕСПЛАТНУЮ доставку каждого заказа! Наша бесплатная доставка в подъезд включает в себя размещение предметов в вашем доме или квартире. Некоторые товары могут иметь право на нашу услугу доставки в белых перчатках, которая включает размещение в комнате по выбору, сборку и удаление упаковки всего за 129 долларов США.!
Возврат: Apt2B предлагает бесплатную 100-дневную политику возврата всех заказов.
Мы искренне хотим, чтобы каждый покупатель остался доволен своей покупкой! Мы предлагаем 100 дней, чтобы испытать наши продукты лично, и отличный сервис для решения любых проблем или проблем на этом пути.Для получения дополнительной информации по вышеуказанному, пожалуйста, посетите нашу страницу доставки и возврата
- Каждое изделие мастерски изготавливается вручную на заказ в Лос-Анджелесе, Калифорния, и в настоящее время собирается за 2–4 недели до отправки вам! Заказы выполняются в порядке живой очереди, поэтому закажите сейчас, чтобы занять место в очереди.
 Получите более подробную информацию здесь. Посмотреть всю коллекцию логан
Получите более подробную информацию здесь. Посмотреть всю коллекцию логан Расслабьтесь на мягких подушках и поднимите ноги после рабочего дня. Наслаждайтесь выбором тканей и просмотрите более 50 различных цветов. Хотите ли вы придерживаться классического оттенка или жаждете чего-то яркого и живого, у нас это есть. На диван Logan предоставляется пожизненная гарантия.
Расслабьтесь на мягких подушках и поднимите ноги после рабочего дня. Наслаждайтесь выбором тканей и просмотрите более 50 различных цветов. Хотите ли вы придерживаться классического оттенка или жаждете чего-то яркого и живого, у нас это есть. На диван Logan предоставляется пожизненная гарантия. Мы искренне хотим, чтобы каждый покупатель остался доволен своей покупкой! Мы предлагаем 100 дней, чтобы испытать наши продукты лично, и отличный сервис для решения любых проблем или проблем на этом пути.
Мы искренне хотим, чтобы каждый покупатель остался доволен своей покупкой! Мы предлагаем 100 дней, чтобы испытать наши продукты лично, и отличный сервис для решения любых проблем или проблем на этом пути.Выбор размера выборки для исследований с повторными измерениями | BMC Medical Research Methodology
Выбор метода анализа данных
Для краткости не будем подробно останавливаться на принципиальном вопросе выбора метода анализа данных. Хотя статистический консалтинг будет иметь значение на любом этапе исследования, более ранние этапы планирования исследования приносят наибольшую пользу от консультирования. Мы предполагаем, что итеративный процесс выбора и уточнения целей исследования, основных результатов и плана выборки увенчался успехом. В свою очередь, мы также предполагаем, что был выбран соответствующий план анализа, который закладывает основу для выбора размера выборки.
Мы предполагаем, что итеративный процесс выбора и уточнения целей исследования, основных результатов и плана выборки увенчался успехом. В свою очередь, мы также предполагаем, что был выбран соответствующий план анализа, который закладывает основу для выбора размера выборки.
Выбор метода анализа мощности
Одним из первых шагов при расчете размера выборки является выбор метода анализа мощности, который адекватно согласуется с методом анализа данных [1]. В качестве примера рассмотрим исследование, в котором исследователь планирует проверить, одинаково ли реагируют на лекарство ветераны и не ветераны. Исследователь планирует контролировать как пол, так и возраст. Запланированный анализ данных представляет собой анализ ковариации (ANCOVA) с возрастом в качестве ковариации. В этом случае расчет объема выборки на основе двухгруппового t-критерия будет нецелесообразным, поскольку запланированный анализ данных не является t-тестом. Несоответствие между планом, используемым для расчета размера выборки, и планом, используемым для анализа данных, может привести к слишком большому или слишком маленькому размеру выборки [1], что способствует получению неубедительных результатов.
На практике смешанные модели стали наиболее популярным методом анализа повторных измерений и продольных данных. Однако проверенные методы мощности и размера выборки существуют только для ограниченного класса смешанных моделей [2]. Кроме того, большинство этих методов основаны на приближениях и делают простые предположения о дизайне исследования. В некоторых случаях запланированный анализ данных не имеет опубликованных методов анализа мощности, соответствующих анализу данных. Один из возможных методов определения надежной мощности или размера выборки, когда нет доступных формул мощности, заключается в проведении исследования с помощью компьютерного моделирования. Мы рекомендуем использовать соответствующее программное обеспечение, которое было протестировано и подтверждено, когда оно доступно. Пакетное программное обеспечение имеет преимущества, заключающиеся в меньшем количестве программирования и меньшей статистической сложности.
Исходя из текущего уровня знаний, мы рекомендуем использовать методы мощности, разработанные для многомерных моделей, для расчета размера выборки для исследований с использованием общих смешанных моделей для анализа данных. Для тщательно построенных смешанных моделей [3, 4] методы мощности, разработанные для многомерных моделей, обеспечивают наилучший доступный анализ мощности. Техническую информацию можно найти у Muller et al. [1], Мюллер и соавт. [5] и Джонсон и др. [6]. Другой вариант — использовать аппроксимацию большой выборки для мощности, описанную Лю и Ляном. Они предложили метод расчета размеров выборки для исследований с коррелированными наблюдениями, основанный на подходе обобщенного оценочного уравнения (GEE1) [7].
Для тщательно построенных смешанных моделей [3, 4] методы мощности, разработанные для многомерных моделей, обеспечивают наилучший доступный анализ мощности. Техническую информацию можно найти у Muller et al. [1], Мюллер и соавт. [5] и Джонсон и др. [6]. Другой вариант — использовать аппроксимацию большой выборки для мощности, описанную Лю и Ляном. Они предложили метод расчета размеров выборки для исследований с коррелированными наблюдениями, основанный на подходе обобщенного оценочного уравнения (GEE1) [7].
Модель сложной дисперсии и моделей корреляции
При планировании исследования с повторными измерениями ученые должны указать модели дисперсии и корреляции среди повторяющихся измерений. Неспособность указать модели дисперсии и корреляции, соответствующие тем, которые будут видны в предлагаемом исследовании, может привести к неправильному анализу мощности [1].
Простейший образец дисперсии предполагает равную дисперсию среди повторных измерений. Например, при измерении математических достижений детей в классе разумно предположить, что в среднем они одинаковы для всех детей. Напротив, измерение математических достижений одних и тех же детей в 6-м, 7-м и 8-м классах может привести к увеличению изменчивости, уменьшению изменчивости или стабильной изменчивости. Вариативность результатов теста определенного навыка может уменьшаться в зависимости от класса из-за стабильного приобретения навыка. С другой стороны, изменчивость результатов стандартизированных тестов может остаться неизменной благодаря тщательному построению тестов разработчиками. Повторные измерения некоторых переменных могут иметь любую возможную дисперсию. Например, в зависимости от экспериментальных условий концентрация метаболитов в крови может увеличиваться, уменьшаться или оставаться неизменной во времени.
Напротив, измерение математических достижений одних и тех же детей в 6-м, 7-м и 8-м классах может привести к увеличению изменчивости, уменьшению изменчивости или стабильной изменчивости. Вариативность результатов теста определенного навыка может уменьшаться в зависимости от класса из-за стабильного приобретения навыка. С другой стороны, изменчивость результатов стандартизированных тестов может остаться неизменной благодаря тщательному построению тестов разработчиками. Повторные измерения некоторых переменных могут иметь любую возможную дисперсию. Например, в зависимости от экспериментальных условий концентрация метаболитов в крови может увеличиваться, уменьшаться или оставаться неизменной во времени.
Что касается шаблонов корреляции, полезно думать о них как о четырех типах с возрастающей сложностью: (1) нулевые корреляции (независимые наблюдения), (2) равные корреляции, (3) шаблоны, основанные на правилах, и (4) неструктурированные корреляции (без определенного паттерна).
Простейшая модель корреляций предполагает постоянную корреляцию, часто называемую внутриклассовой корреляцией, между всеми наблюдениями. Если каждое наблюдение фиксирует какой-то аспект успеваемости ребенка в классе, то предположение об общей корреляции между любыми двумя детьми кажется разумным. Напротив, если один и тот же ребенок измеряется в 6, 7 и 8 классах, мы ожидаем, что корреляция между 6 и 8 классами будет ниже, чем корреляция между 6 и 7 классами. Корреляции между повторными измерениями одного участника обычно различаются. во времени плавным и упорядоченным образом. Измерения, проведенные близко во времени, обычно более коррелированы, чем измерения, проведенные дальше друг от друга во времени.
Если каждое наблюдение фиксирует какой-то аспект успеваемости ребенка в классе, то предположение об общей корреляции между любыми двумя детьми кажется разумным. Напротив, если один и тот же ребенок измеряется в 6, 7 и 8 классах, мы ожидаем, что корреляция между 6 и 8 классами будет ниже, чем корреляция между 6 и 7 классами. Корреляции между повторными измерениями одного участника обычно различаются. во времени плавным и упорядоченным образом. Измерения, проведенные близко во времени, обычно более коррелированы, чем измерения, проведенные дальше друг от друга во времени.
Многие шаблоны корреляции на основе правил были разработаны в контексте моделей временных рядов. Одним из распространенных примеров шаблона на основе правил является авторегрессия первого порядка (AR1), частный случай семейства авторегрессии первого порядка с линейной экспонентой (LEAR) [8]. AR1 и более общие шаблоны LEAR предполагают, что корреляции между повторными измерениями экспоненциально снижаются со временем или расстоянием. Например, в исследованиях боли, в которых изучается влияние вмешательств на память пациентов о боли после лечения, корреляции между измерениями памяти о боли у одного и того же пациента со временем обычно уменьшаются. Связь между памятью о боли и течением времени можно смоделировать с помощью структуры LEAR.
Например, в исследованиях боли, в которых изучается влияние вмешательств на память пациентов о боли после лечения, корреляции между измерениями памяти о боли у одного и того же пациента со временем обычно уменьшаются. Связь между памятью о боли и течением времени можно смоделировать с помощью структуры LEAR.
Шаблон неструктурированной корреляции предполагает, что среди повторяющихся измерений нет конкретных шаблонов корреляции. Каждая корреляция между любыми двумя повторными измерениями может быть уникальной. Неструктурированный образец корреляции требует знания p × (p−1)/2 различных корреляций, где p — количество повторных измерений.
Обычно предполагается, что все участники исследования демонстрируют одинаковую картину корреляции. Доступны статистические методы, позволяющие установить различные модели корреляции среди участников исследования. Хотя добросовестный анализ данных используется редко, он должен включать содержательную оценку достоверности однородности корреляционного паттерна среди групп участников.
Каждый из шаблонов корреляции имеет ограничения. Структурированные модели корреляции отражают особые предположения о корреляциях между повторяющимися измерениями. Предположения вводят риск выбора слишком простого шаблона, который может ложно завышать частоту ошибок первого рода [3]. Например, шаблон равной корреляции предполагает, что любая пара наблюдений имеет одинаковую корреляцию, независимо от того, насколько далеко они отстоят друг от друга во времени. С другой стороны, выбор неструктурированного шаблона корреляции может быть нецелесообразным, поскольку он требует оценки большего количества параметров, чем поддержка данных, что приводит к невозможности сходимости. Гибкая структура, такая как шаблон LEAR, часто обеспечивает наилучший компромисс между слишком малой сложностью (равная корреляция) и слишком большой (неструктурированная корреляция).
Поиск допустимых входных данных для расчета размера выборки
Мы проиллюстрируем, как найти достоверные входные данные для расчета размера выборки, на примере клинического исследования, в котором в качестве результатов использовались повторные измерения зубной боли. Исследователь планирует рандомизировать участников исследования в одну из двух групп: контрольную или лечебную. Знание шкалы боли позволяет предположить, что данные имеют нормальное распределение. Входными данными, необходимыми для вычисления размера выборки, являются (1) α, частота ошибок типа I, (2) предикторы, подразумеваемые планом, (3) проверяемая целевая гипотеза, (4) разница в структуре средних для какая хорошая мощность ищется, (5) дисперсии переменных ответа и (6) корреляции между переменными ответа (таблица 1). Поиск последних трех элементов в списке требует больших усилий.
Исследователь планирует рандомизировать участников исследования в одну из двух групп: контрольную или лечебную. Знание шкалы боли позволяет предположить, что данные имеют нормальное распределение. Входными данными, необходимыми для вычисления размера выборки, являются (1) α, частота ошибок типа I, (2) предикторы, подразумеваемые планом, (3) проверяемая целевая гипотеза, (4) разница в структуре средних для какая хорошая мощность ищется, (5) дисперсии переменных ответа и (6) корреляции между переменными ответа (таблица 1). Поиск последних трех элементов в списке требует больших усилий.
Полноразмерная таблица
Ученые, разрабатывающие исследование, обычно знают частоту ошибок типа I, предикторы и целевую гипотезу. Частота ошибок типа I (α), выбранная учеными, представляет собой вероятность утверждения о существовании эффекта, хотя на самом деле его нет (обычно устанавливается на уровне 0,01 или 0,05).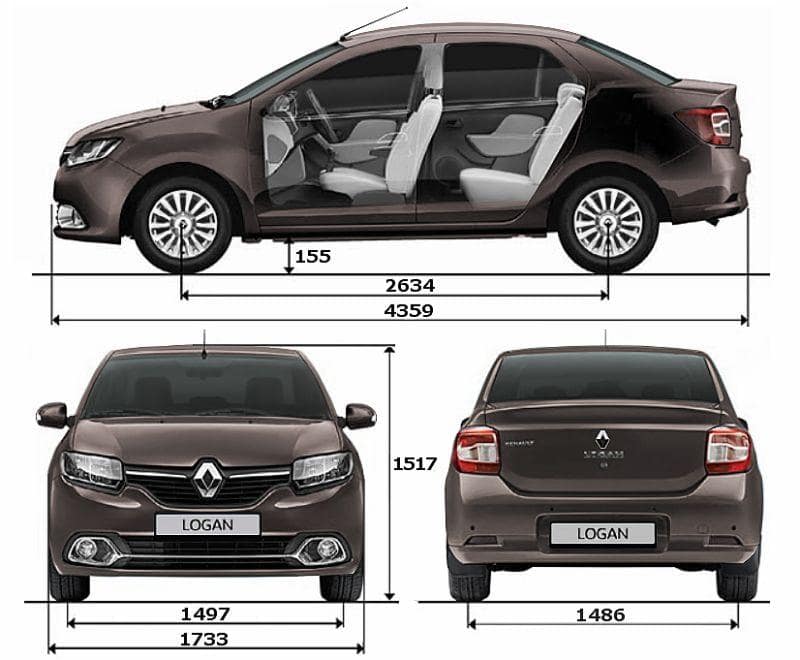
Ученые должны указать наименьшее научно важное различие. В примере с зубной болью ученые должны указать минимальную разницу в средних значениях боли, которую они считают важной. Исследователи, разрабатывающие исследование, должны сделать осознанный выбор средней разности интереса. Для боли, измеряемой по непрерывной шкале от 0 до 5, изменение уровня боли на 0,5 может не иметь клинического значения, тогда как изменение на 1,0 может считаться исследователями важным.
Ученые также должны указать дисперсию каждого из повторных измерений. Для выбора значения дисперсии можно использовать несколько стратегий: (1) ее можно оценить на основе данных предыдущих исследований, (2) ее можно оценить на основе данных пилотного исследования или (3) это может быть обоснованное предположение, основанное на опыт. В лучшем случае можно получить хорошую оценку дисперсии из предыдущего исследования.
При использовании оценки из предыдущего исследования важно отметить, что дисперсия, необходимая для расчета размера выборки, представляет собой остаточную дисперсию. Остаточная дисперсия — это дисперсия, не объясненная предикторами. Нескорректированная дисперсия переменной отклика содержит вариацию из-за предикторных переменных, включенных в предыдущее исследование. Одни и те же предикторы могут не включаться в планируемое исследование. Предположим, новое исследование будет включать переменную ответа относительно однородной по возрасту группы населения (например, студентов колледжа в крупном государственном университете Верхнего Среднего Запада). Исследователю необходимо оценить отклонение от предыдущего исследования, в котором переменная ответа измерялась у людей всех возрастов.
Для анализа мощности повторных измерений требуется не одно, а набор значений дисперсии. Как обсуждалось ранее, научный контекст может обеспечить разумное ожидание закономерности изменения дисперсии. На практике часто можно оценить одно значение дисперсии на основе данных, а затем указать другие дисперсии на основе ожидаемой тенденции дисперсии. Научный контекст часто обеспечивает разумную модель. В целом, рост, обучение и другие процессы развития обычно приводят к монотонно уменьшающейся дисперсии, в то время как старение, болезни и другие модели деградации часто приводят к монотонно возрастающей дисперсии.
Ученые также должны указать корреляции между парами измерений. Те же основные стратегии выбора дисперсии применимы и для выбора корреляции. Часто можно оценить одно значение корреляции на основе данных, а затем указать другие корреляции на основе шаблона корреляции. Когда необходимы обоснованные предположения, опыт исследователя и научные ограничения определяют выбор корреляции. Например, ученые-бихевиористы могут рассчитывать на надежность опроса в диапазоне от 0,25 до 0,75, в то время как инженер-биомедик может рассчитывать на надежность приборов не менее 0,9.0. Как и в случае с дисперсиями, выбранная корреляция должна быть остаточной корреляцией, то есть корреляцией между остатками для повторных измерений.
Когда необходимы обоснованные предположения, опыт исследователя и научные ограничения определяют выбор корреляции. Например, ученые-бихевиористы могут рассчитывать на надежность опроса в диапазоне от 0,25 до 0,75, в то время как инженер-биомедик может рассчитывать на надежность приборов не менее 0,9.0. Как и в случае с дисперсиями, выбранная корреляция должна быть остаточной корреляцией, то есть корреляцией между остатками для повторных измерений.
Выберите правильное программное обеспечение
Многие пакеты программного обеспечения и интернет-программы доступны для расчета размера выборки для t-тестов, различных ANOVA и регрессионных моделей. Небольшое количество программ охватывает ограниченный диапазон планов повторных измерений. Некоторые из программ бесплатны и просты в установке и использовании, но им не хватает возможностей для работы со сложными проектами. Например, апплеты Java, разработанные Lenth (http://www.stat.uiowa.edu/~rlenth/Power/), обеспечивают оценку мощности для определенных линейных моделей, таких как t-тесты, ANOVA и исследования линейной регрессии [9]. ]. Некоторые программы являются коммерческими продуктами, которые можно использовать для широкого круга планов исследований, но они могут быть непомерно дорогими, а также могут требовать больших знаний в области статистических теорий и сильных навыков компьютерного программирования. Например, POWERLIB — это бесплатный модуль SAS/IML, который вычисляет размер выборки и мощность для широкого спектра общих линейных одномерных и многомерных моделей [6]. Однако для использования этой программы требуется лицензия на программное обеспечение SAS, глубокие знания статистических теорий и навыки программирования SAS. Power Analysis and Sample Size (PASS, NCSS) вычисляет размер выборки для ряда многомерных моделей (как линейных, так и нелинейных), но это коммерческий продукт, который необходимо приобрести и установить на свой компьютер. Некоторые программы делают простые статистические предположения, и эти предположения ограничивают их полезность. Например, Optimal Design (OD) — это бесплатная программа для определения размера выборки с графическим пользовательским интерфейсом (GUI), которая позволяет пользователям вычислять размер выборки для лонгитюдных исследований с многоуровневыми планами [10].
]. Некоторые программы являются коммерческими продуктами, которые можно использовать для широкого круга планов исследований, но они могут быть непомерно дорогими, а также могут требовать больших знаний в области статистических теорий и сильных навыков компьютерного программирования. Например, POWERLIB — это бесплатный модуль SAS/IML, который вычисляет размер выборки и мощность для широкого спектра общих линейных одномерных и многомерных моделей [6]. Однако для использования этой программы требуется лицензия на программное обеспечение SAS, глубокие знания статистических теорий и навыки программирования SAS. Power Analysis and Sample Size (PASS, NCSS) вычисляет размер выборки для ряда многомерных моделей (как линейных, так и нелинейных), но это коммерческий продукт, который необходимо приобрести и установить на свой компьютер. Некоторые программы делают простые статистические предположения, и эти предположения ограничивают их полезность. Например, Optimal Design (OD) — это бесплатная программа для определения размера выборки с графическим пользовательским интерфейсом (GUI), которая позволяет пользователям вычислять размер выборки для лонгитюдных исследований с многоуровневыми планами [10]. Однако при расчетах повторных измерений используются чрезмерно упрощающие предположения о равных дисперсиях и корреляциях. По нашему опыту, хотя дисперсия в продольных данных в некоторых случаях может оставаться стабильной, корреляция никогда не бывает.
Однако при расчетах повторных измерений используются чрезмерно упрощающие предположения о равных дисперсиях и корреляциях. По нашему опыту, хотя дисперсия в продольных данных в некоторых случаях может оставаться стабильной, корреляция никогда не бывает.
Некоторые программы из основных программных пакетов имеют встроенные опции для расчета размера выборки, но только для одномерных планов. Во время написания настоящей рукописи к этим программам относятся nQuery (nQuery Advisor, Statistical Solutions), SAS (GLMpower, SAS Institute Inc.) и SPSS (SamplePower, IBM Corporation). Учитывая продолжающуюся эволюцию программного обеспечения, мы призываем читателя убедиться, что выбранное программное обеспечение обладает необходимыми возможностями и функциями и соответствует профессиональным стандартам статистических методов и точности программирования.
Как правило, программные пакеты с графическим интерфейсом проще в использовании, чем пакеты с интерфейсом командной строки. Однако одним из преимуществ использования интерфейсов командной строки является то, что они позволяют легко документировать и совместно использовать весь процесс анализа мощности. Разработанный компьютерный код можно легко передать коллегам для просмотра и повторного использования в других наборах данных. Для воспроизводимых исследований рекомендуется документировать всю мощность и процесс анализа данных, независимо от того, какой программный пакет используется.
Разработанный компьютерный код можно легко передать коллегам для просмотра и повторного использования в других наборах данных. Для воспроизводимых исследований рекомендуется документировать всю мощность и процесс анализа данных, независимо от того, какой программный пакет используется.
Мы рекомендуем программу GLIMMPSE (URL: http://glimmpse.samplesizeshop.org/) для расчета размера выборки для повторных измерений и продольных планов. GLIMMPSE — это бесплатная интернет-программа, которая имеет два режима: режим разработки матричного исследования и режим разработки управляемого исследования. Режим проектирования матричного исследования предназначен для пользователей с продвинутой статистической подготовкой, а режим управляемого исследования предназначен для исследователей-прикладников. GLIMMPSE не требует предыдущего опыта программирования и предоставляет пошаговый, удобный интерфейс, помогающий исследователям выполнять расчеты размера выборки и мощности. Кроме того, GLIMMPSE позволяет сохранять предоставленный дизайн исследования для будущих ссылок. GLIMMPSE поддерживает линейные модели с фиксированными переменными-предикторами и линейные модели с фиксированными переменными-предикторами плюс одна гауссовская ковариата [11–13]. GLIMMPSE предлагает множество шаблонов дисперсии и корреляции. Программа была тщательно протестирована, результаты проверки доступны на веб-сайте.
GLIMMPSE поддерживает линейные модели с фиксированными переменными-предикторами и линейные модели с фиксированными переменными-предикторами плюс одна гауссовская ковариата [11–13]. GLIMMPSE предлагает множество шаблонов дисперсии и корреляции. Программа была тщательно протестирована, результаты проверки доступны на веб-сайте.
Расчет размера выборки для исследования зубной боли
В этом разделе мы используем реальный пример, чтобы проиллюстрировать процесс сбора информации для расчета размера выборки для плана повторных измерений. Для расчета используется режим Guided Study Design программы GLIMMPSE, но исследователь должен будет выполнить те же действия для сбора необходимой информации, даже если предпочтительнее использовать другую программу. Поэтому описание технических деталей GLIMMPSE сведено к минимуму. Руководство по использованию GLIMMPSE доступно на http://www.samplesizeshop.org.
Обзор исследования боли
В предыдущем исследовании терапевтических вмешательств при острой боли Logan et al. обнаружили, что вмешательство, инструктирующее пациентов обращать внимание только на физические ощущения во рту, может значительно снизить интенсивность сенсорной боли во время лечения корневых каналов у пациентов, у которых было как сильное стремление к контролю, так и низкий воспринимаемый контроль [14]. Поскольку предыдущая работа показала, что поведение избегания строится в результате воспоминаний о боли [15–18], исследователи теперь планируют дополнительно изучить долгосрочные эффекты сенсорной фокусировки на восприятии боли. Новый набор участников будет набран и отслежен с течением времени. В новом исследовании будет изучено изменение памяти каждого участника о боли.
обнаружили, что вмешательство, инструктирующее пациентов обращать внимание только на физические ощущения во рту, может значительно снизить интенсивность сенсорной боли во время лечения корневых каналов у пациентов, у которых было как сильное стремление к контролю, так и низкий воспринимаемый контроль [14]. Поскольку предыдущая работа показала, что поведение избегания строится в результате воспоминаний о боли [15–18], исследователи теперь планируют дополнительно изучить долгосрочные эффекты сенсорной фокусировки на восприятии боли. Новый набор участников будет набран и отслежен с течением времени. В новом исследовании будет изучено изменение памяти каждого участника о боли.
Шаг 1: Укажите цель исследования
Эффективность терапевтического вмешательства при острой боли часто определяется путем измерения и сравнения интенсивности боли, которую пациент испытал и вспомнил. Однако предыдущие исследования показали, что на кратковременную (от часов до дней) и долговременную (месяцы) память о боли могут влиять разные факторы [18]. Утверждалось, что кратковременная память о боли является точным отражением количества боли, испытанной во время стимула, поскольку воспоминание и переживание связаны во времени. С другой стороны, на долговременную память о боли больше могут влиять как временные факторы, так и когнитивные и аффективные факторы, многие из которых могут иметь незначительное отношение к исходному болевому событию. Таким образом, основная цель нового исследования, предложенная исследователями, состоит в том, чтобы определить, имеют ли пациенты, которым предписано использовать сенсорный фокус, иной характер долговременной памяти о боли, чем пациенты, которым этого не нужно.
Утверждалось, что кратковременная память о боли является точным отражением количества боли, испытанной во время стимула, поскольку воспоминание и переживание связаны во времени. С другой стороны, на долговременную память о боли больше могут влиять как временные факторы, так и когнитивные и аффективные факторы, многие из которых могут иметь незначительное отношение к исходному болевому событию. Таким образом, основная цель нового исследования, предложенная исследователями, состоит в том, чтобы определить, имеют ли пациенты, которым предписано использовать сенсорный фокус, иной характер долговременной памяти о боли, чем пациенты, которым этого не нужно.
Шаг 2: Уточните гипотезу
С помощью плана повторных измерений мы можем проверить основной эффект вмешательства, с помощью которого сравниваются средние эффекты вмешательства, усредненные по повторным измерениям. Мы также можем тестировать тенденции во времени. В этом исследовании исследователи заинтересованы в том, чтобы узнать, отличается ли тенденция изменений между группой вмешательства и группой невмешательства. Таким образом, первичная гипотеза исследования может быть формально сформулирована как тест на наличие взаимодействия «время × вмешательство». Гипотетические тенденции болевой памяти для обеих групп показаны на рисунке 1.
Таким образом, первичная гипотеза исследования может быть формально сформулирована как тест на наличие взаимодействия «время × вмешательство». Гипотетические тенденции болевой памяти для обеих групп показаны на рисунке 1.
Гипотетические тенденции болевой памяти.
Полноразмерное изображение
Шаг 3: Задайте переменные отклика
Основной интересующей переменной отклика является память о боли. Это непрерывная переменная, которая находится в диапазоне от 0 до 5,0, где 0 означает отсутствие памяти о боли, а 5,0 означает максимальную память о боли [14]. Память боли будет оцениваться сразу после стоматологической процедуры (Боль 0 ), неделю спустя (Боль 1 ), шесть месяцев спустя (Боль 2 ) и двенадцать месяцев спустя (Боль 3 ). Боль 0 будет измерена в клинике. Боль 1 , Боль 2 и Боль 3 будут измеряться с помощью телефонных интервью. Интервал в повторных измерениях выбирается на основе знаний исследователей о том, как память о боли меняется с течением времени.
Интервал в повторных измерениях выбирается на основе знаний исследователей о том, как память о боли меняется с течением времени.
Шаг 4. Укажите переменные-предикторы
Основным предиктором, представляющим интерес, является вмешательство (т. е. звуковая инструкция для участников использовать сенсорную фокусировку во время соответствующих стоматологических процедур). В новом исследовании индекс стоматологического контроля штата Айова (IDCI) будет использоваться для классификации и отбора пациентов [19].]. Будут набраны только пациенты с высоким желанием контроля и низким ощущением контроля. Пациенты в этой группе будут отобраны и случайным образом распределены либо на вмешательство, либо на отсутствие вмешательства. Участники группы вмешательства будут слушать автоматические аудиоинструкции, в которых им будет предложено уделять пристальное внимание только физическим ощущениям во рту [14]. Пациенты в группе без вмешательства будут слушать автоматические звуковые инструкции на нейтральную тему, чтобы контролировать эффекты СМИ и внимания. Как и в более ранних исследованиях, будут использоваться соответствующие манипулятивные проверки [14].
Как и в более ранних исследованиях, будут использоваться соответствующие манипулятивные проверки [14].
Шаг 5. Определение закономерностей дисперсии и корреляции
После определения целей и переменных следующим шагом является определение закономерностей дисперсии и корреляции между повторяющимися показателями. В нашем случае дисперсия разницы между Pain 0 составила 0,96 в предыдущем исследовании, проведенном исследователями [14]. Эта дисперсия разности может быть непосредственно использована в качестве оценки дисперсии показателей памяти боли, Var(Pain i ). Что касается необходимых корреляций, необходимо оценить 6 значений корреляции, поскольку есть 4 повторных измерения (таблица 2). Предыдущие исследования сообщают, что корреляция между пережитой болью и воспоминанием о боли в течение 1 недели составляет 0,60, а корреляция между пережитой болью и воспоминанием о боли в течение 18 месяцев составляет 0,39.[18]. Следовательно, разумно полагать, что корреляция между Болью 0 и Болью 1 составляет 0,60. Кроме того, поскольку исследователи считают, что корреляции плавно затухают во времени, разумно принять Боль 0 — Боль 1 , Боль 0 — Боль 2 и Боль 0 — Боль 3 Все корреляции больше 0,39. Основываясь на тенденции затухания и ограничительной нижней границе 0,39, исследователи подсчитали, что боль 0 — Боль 1 , Боль 0 — Боль 2 и Боль 0 — Боль 3 корреляции составляют примерно 0,6, 0,5 и 0,4 соответственно (второй столбец в таблице 2). Следуя аналогичному мысленному процессу, исследователи подсчитали, что корреляции Боль 1 — Боль 2 , Боль 1 — Боль 3 и Боль 2 — Боль 3 составляют примерно 0,45 и 0,45, и 0,45. соответственно (таблица 2).
Кроме того, поскольку исследователи считают, что корреляции плавно затухают во времени, разумно принять Боль 0 — Боль 1 , Боль 0 — Боль 2 и Боль 0 — Боль 3 Все корреляции больше 0,39. Основываясь на тенденции затухания и ограничительной нижней границе 0,39, исследователи подсчитали, что боль 0 — Боль 1 , Боль 0 — Боль 2 и Боль 0 — Боль 3 корреляции составляют примерно 0,6, 0,5 и 0,4 соответственно (второй столбец в таблице 2). Следуя аналогичному мысленному процессу, исследователи подсчитали, что корреляции Боль 1 — Боль 2 , Боль 1 — Боль 3 и Боль 2 — Боль 3 составляют примерно 0,45 и 0,45, и 0,45. соответственно (таблица 2).
Полноразмерная таблица
Шаг 6: Создайте кривую мощности и выберите соответствующий размер выборки
В GLIMMPSE пользователю предлагается ввести желаемые значения мощности, частоты ошибок типа I, переменные плана исследования, дисперсии и корреляции. После того, как эти данные будут введены, GLIMMPSE покажет меню возможных гипотез для введенного дизайна исследования (рис. 2). Возможные гипотезы для схемы повторных измерений включают тестирование основного эффекта вмешательства, тенденции во времени и взаимодействие времени и вмешательства. Для нашего исследования боли в GLIMMPSE была выбрана гипотеза, проверяющая взаимодействие времени и вмешательства.
После того, как эти данные будут введены, GLIMMPSE покажет меню возможных гипотез для введенного дизайна исследования (рис. 2). Возможные гипотезы для схемы повторных измерений включают тестирование основного эффекта вмешательства, тенденции во времени и взаимодействие времени и вмешательства. Для нашего исследования боли в GLIMMPSE была выбрана гипотеза, проверяющая взаимодействие времени и вмешательства.
Страница гипотез в GLIMMPSE.
Полноразмерное изображение
Результаты анализа мощности представлены на рисунке 3. По оси Y отложена мощность, а по оси X — средняя разница между измерениями Pain i (например, Pain 2 — Pain 1 ). Как видно на рисунке 3, для заданной желаемой мощности минимальная обнаруживаемая разница средних значений уменьшается по мере увеличения размера выборки. Исследователи определили минимальное изменение боли, которое они считают клинически важным, как разницу в 1,2 между показателями боли.