Коли потрібно робити розвал сходження? І як зрозуміти, що час настав?
Якщо проводиш «третє життя» за кермом, той час, коли потрібно робити розвал сходження розумієш інтуїтивно. Як автомобіль показує себе на дорозі, як він веде при проїзді дорожніх нерівностей, і навіть по звуку шин. Але автомобілісту-початківцю визначитися з тим, коли роблять розвал сходження — це таємниця велика є. Спробуємо демонтувати з неї покриви!
Що таке розвал-сходження?
Розвал — кут, який утворюють вертикальна вісь і площину обертання колеса. Буває негативним – коли колеса нахилені верхньою стороною всередину (до центральної лінії автомобіля). І позитивним, при якому верхня сторона коліс відхилена назовні від центральної лінії авто.
Сходження – кут, утворений лінією напрямку руху автомобіля, та площиною обертання колеса. Також може бути негативний – коли задній край колеса спрямований до центру автомобіля (у цьому випадку можна говорити про розбіжність). І позитивний – коли передній край коліс розташований ближче до центральної осі авто.
І позитивний – коли передній край коліс розташований ближче до центральної осі авто.
Таким чином, розвал-сходження – це два основні параметри положення коліс транспортного засобу. Коли потрібно регулювати ці параметри? При кожному втручанні в конструкцію підвіски це обов’язково. І періодично – для профілактики, щоб виставлені кути не збивалися (а збити їх намагаються усі дорожні нерівності).
Що буде, якщо цю процедуру не робити? Ось перелік наслідків:
- погіршення керованості — як правило, автомобіль починає тягнути в той чи інший бік,
- на кермі з’являється биття,
- машина не стоїть на прямій;
- прискорене зношування гуми — розвал, перевищений на кілька міліметрів, може привести абсолютно нову гуму в стан непридатності через тисячу кілометрів;
- підвищене споживання палива – при збитих кутах витрата пального збільшується загалом на 10%.
Тепер давайте поговоримо про те, коли треба робити розвал сходження коліс, і як зрозуміти, що потрібно робити розвал сходження.
Коли потрібно регулювати?
Чесно? Чим частіше, тим краще! Тому що, як уми вже сказали, невеликі відхилення мають великі впливи, а ударні навантаження на підвіску «прилітають» постійно. Але звісно, щодня перед поїздкою на роботу таку процедуру проходити не вдасться. Тому давайте спробуємо відповісти на питання щодо частоти регулювання, які звучать найчастіше.
Чи потрібно робити розвал після заміни стояків? Багато в чому це залежить від марки автомобіля, але навіть якщо у вас при заміні стійки кути геометрії не порушуються, краще процедуру все ж таки при нагоді пройти. Особливо якщо автомобіль свіжий — для літніх авто відхилення в 1-2 мм, яке могло утворитися, ще допустимо, а допуски в сучасних автомобілях дуже жорсткі. Плюс до всього, ходова машина є складною системою, де всі елементи пов’язані один з одним в єдиний механізм, і заміна однієї частини може позначатися на інших.
Якщо проводиться заміна кульовий, чи потрібно робити розвал? В цьому випадку затягувати точно не варто. Процедура регулювання розвалу-сходження у разі обов’язкова. Для тих, хто цікавиться, можемо пояснити – саме кульові опори забезпечують правильну просторову орієнтацію коліс, і це головний елемент налаштування ходової частини. Тому, чи потрібно робити розвал-сходження після заміни кульової? Обов’язково!
Процедура регулювання розвалу-сходження у разі обов’язкова. Для тих, хто цікавиться, можемо пояснити – саме кульові опори забезпечують правильну просторову орієнтацію коліс, і це головний елемент налаштування ходової частини. Тому, чи потрібно робити розвал-сходження після заміни кульової? Обов’язково!
Чи потрібно робити розвал після заміни підшипників (ступичних чи опорних)? Ремонт маточини не передбачає мінімального розбирання підвіски, проте виробники настійно рекомендують і в цьому випадку виставляти кути коліс. Справа в тому, що в міру зношування деталей, параметри ходової частини змінюються, і щоразу проводячи їх регулювання, Ви нівелюєте відхилення. Із заміною підшипників система як би повертається у вихідний стан, а загальне налаштування залишається незмінним. Якщо не хочете весь час «ловити» автомобіль на прямих — робіть розвал/сходження.
Чи потрібно робити розвал після заміни сайлентблоків? При заміні сайлентблоків кути точно йдуть, тому розвал сходження робити обов’язково. Ситуація точно повторює опис з попереднього пункту – підвіска була налаштована під параметри зношених гумово-металевих втулок, а вони були замінені на нові. Після заміни сайлентблоків обов’язково потрібно робити розвал та сходження незалежно від моделі автомобіля.
Ситуація точно повторює опис з попереднього пункту – підвіска була налаштована під параметри зношених гумово-металевих втулок, а вони були замінені на нові. Після заміни сайлентблоків обов’язково потрібно робити розвал та сходження незалежно від моделі автомобіля.
Після заміни амортизаторів потрібно робити східний розвал чи ні? Обов’язково потрібно. Більше того, процедуру проводять не тільки при заміні стійок у зборі, але і після заміни будь-якої їх частини, тобто при заміні пружин теж потрібно робити розвал! Амортизатор — це одна з найважливіших частин ходової частини, його заміна завжди призводить до зміни параметрів.
Після заміни важелів чи потрібно робити сход розвал? Чомусь багато автомобілістів, особливо старого загартування, вважають, що розвал треба робити тільки якщо з важелями змінювалися і наконечники. У автовиробників на це рахунок інша думка, і довіряти їм слід все ж таки більше, ніж порадам сусідів по гаражу. При заміні цих деталей підвіски сход-розвал слід проводити. Або хоча б перевірити його параметри на комп’ютерному стенді з набором датчиків. Ця процедура не дорога, а зрозуміти стан автомобіля допомагає досить добре.
Або хоча б перевірити його параметри на комп’ютерному стенді з набором датчиків. Ця процедура не дорога, а зрозуміти стан автомобіля допомагає досить добре.
Щоб не затягувати занадто, скажемо, що після заміни пильовика потрібно робити розвал, і після ремонту рейки потрібно робити розвал сходження! А якщо була заміна приводу, чи потрібно робити розвал? І після заміни приводу теж треба робити його! Як тепер думаєте, чи потрібно робити розвал після заміни коліс? Правильно! Обов’язково потрібно. Будь-яке втручання у підвіску – це зміна кутів розташування коліс. І в будь-якому випадку їх необхідно виставляти у правильне положення.
Давайте розберемо ситуації без втручання у підвіску. Як це не парадоксально, на нещодавно купленому новому автомобілі процедуру розвалу-сходження доведеться робити частіше. Поки деталі підвіски не притерлися, процедуру розвалу краще проводити раз на п’ять тисяч кілометрів пробігу. Це забезпечить правильну обкатку всієї ходової частини.
Коли обкатка пройдена, перевірка кутів розвалу-сходження проводиться раз на п’ятнадцять-двадцять тисяч кілометрів пробігу. Найкраще на проходження процедури прибувати після заміни гуми з літньої на зимову, і навпаки. Якщо втручання у підвіску був, то інтервал двічі на рік оптимальним. Чому сход/розвал йде? Просідає кліренс, деталі підвіски зсуваються щодо один одного. Як зрозуміти, що потрібно робити розвал сходження на автомобілі за його поведінкою на дорозі? Якщо у керма немає чіткого положення «нуля», якщо автомобіль починає «гуляти» при їзді на прямій, або якщо його веде убік – це всі ознаки невідрегульованих розвалів-сходження. Правильний знак — з’їдена тільки на певних ділянках коліс гума.
Найкраще на проходження процедури прибувати після заміни гуми з літньої на зимову, і навпаки. Якщо втручання у підвіску був, то інтервал двічі на рік оптимальним. Чому сход/розвал йде? Просідає кліренс, деталі підвіски зсуваються щодо один одного. Як зрозуміти, що потрібно робити розвал сходження на автомобілі за його поведінкою на дорозі? Якщо у керма немає чіткого положення «нуля», якщо автомобіль починає «гуляти» при їзді на прямій, або якщо його веде убік – це всі ознаки невідрегульованих розвалів-сходження. Правильний знак — з’їдена тільки на певних ділянках коліс гума.
Короткі підсумки
Незважаючи на те, що є низка автовласників, які стверджують, що сход/розвал треба робити лише в кількох певних випадках, ми рекомендуємо робити розвал/сходження раз на півроку при сезонній зміні гуми, якщо не було втручань у підвіску. Якщо у підвісці щось ремонтувалося, то розвал-сходження – це обов’язкова процедура одразу після ремонту. Погляньте на автомобілі тих, хто стверджує, що налаштування кутів розвалу/сходження не потрібне. Як правило, їм не тільки розвал/сходження не допоможе, але навіть заміна двигуна на новий вже не змусить їхати. Вчасно зроблений розвал-сходження обійдеться дешевше, ніж комплект новеньких покришок, і куди дешевше Вашої безпеки на дорозі. Тому якщо автомобілем стало важко керувати, якщо його доводиться раз у раз «ловити» кермом і з’явилося видиме зношування покришок – це чіткий сигнал до відправки на пункт СТО. Залишається вирішити, куди їхати.
Як правило, їм не тільки розвал/сходження не допоможе, але навіть заміна двигуна на новий вже не змусить їхати. Вчасно зроблений розвал-сходження обійдеться дешевше, ніж комплект новеньких покришок, і куди дешевше Вашої безпеки на дорозі. Тому якщо автомобілем стало важко керувати, якщо його доводиться раз у раз «ловити» кермом і з’явилося видиме зношування покришок – це чіткий сигнал до відправки на пункт СТО. Залишається вирішити, куди їхати.
Де краще робити схід-розвал?
СТО «Platinum service» має прогресивні комп’ютерні стенди з встановлення кутів розвалу/сходження. Виміри обов’язково проводяться з урахуванням тиску в шинах, в завантаженому та розвантаженому авто. Навіть якщо виробником були задані нульові допуски – ми легко вирішимо це завдання. Бажаєте виставити сход-розвал правильно і чітко? Милості просимо у «Platinum service». Крім того, майстри центру можуть провести й інші види ремонту/техобслуговування (ремонт КПП, інжектора, гальмівної системи). СТО розташоване всього за десять хвилин їзди від центру міста Дніпро, має лінії найсучаснішого обладнання, і при цьому утримує прайс-лист своїх послуг на демократичному для клієнтів рівні. Звертайтесь – ми завжди будемо раді допомогти, і що б не трапилося з Вашим автомобілем, приведемо його до ладу!
Звертайтесь – ми завжди будемо раді допомогти, і що б не трапилося з Вашим автомобілем, приведемо його до ладу!
ЦІНИ НА ПОСЛУГИ РОЗВАЛ-ПОХОДЖЕННЯ В PLATINUM SERVICE:
Передня вісь: 350 грн
Развал схождение
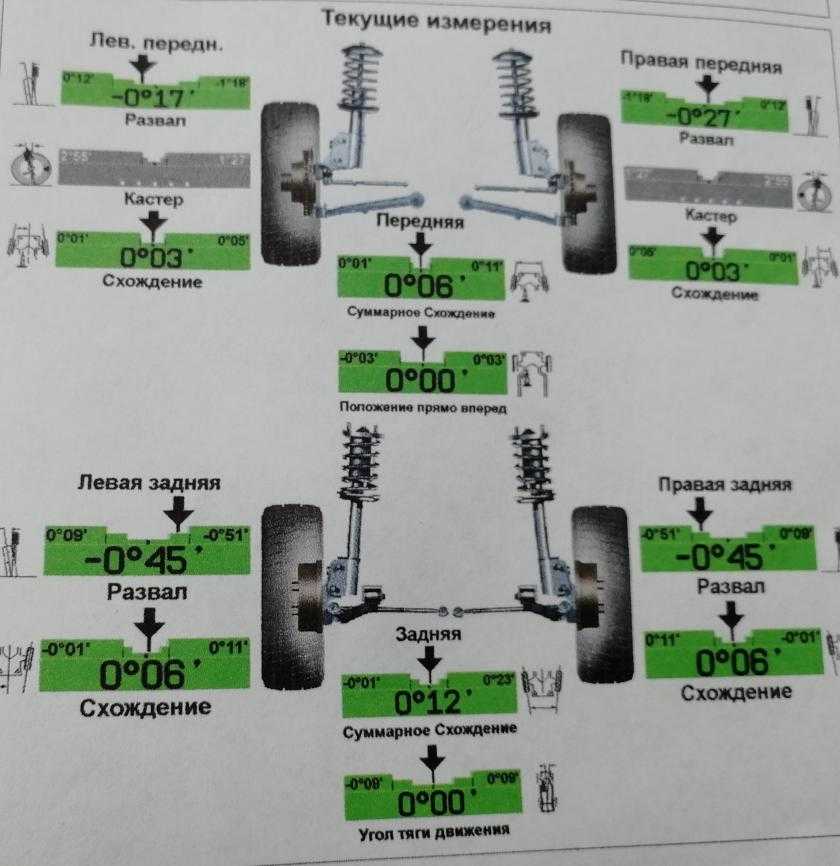
При определенных пробегах подвеска автомобиля требует профилактических мероприятий. Одно из которых – проведение регулировки углов установки колес или, проще говоря, сход-развал.
Правильность установки углов развала и схождения колес обеспечивает управляемость и курсовую устойчивость автомобиля. Облегчается процесс маневрирования и снижается склонность к заносам. Сход-развал на автомобилях также влияет на износ резины и расход топлива.
Рекомендуем придерживаться следующей периодичности регулировку сход-развала на автомобилях – 1 раз в год или 1 раз в 15 тысяч километров. Это позволит сохранить нормативные углы установки колес и продлить срок службы элементов подвески и шин. Однако случаются ситуации, когда требуется незапланированное вмешательство:
Однако случаются ситуации, когда требуется незапланированное вмешательство:
- Неравномерный износ резины
- После работ по замене элементов подвески (наконечники, рычаги и т.д.)
- Автомобиль отклоняется от заданной траектории
- Руль стоит не ровно при прямолинейном движении
- После наезда на препятствие, попадания в глубокую яму
- Руль с трудом возвращается в нулевое положение
Сервисный центр «Авторемстрой» имеет специализированный стенд «3D» для проведения диагностики и регулировки сход-развала . Данный стенд позволяет точно определить положение колес и произвести корректировку их положения согласно рекомендациям завода-изготовителя.
| № п/’п | Модель автомобиля | Стоимость с НДС 20% | |
|---|---|---|---|
| Проверка и регулировка | |||
| 1 | ВАЗ, Лада, ИЖ, Датцун Ондо | 550 | 1100 |
| 2 | УАЗ, Ларгус, Веста, Х-Рэй | 600 | 1200 |
| 3 | Газель НЕКСТ | 900 | 1800 |
| 4 | ГАЗ Соболь, Газель | 700 | 1400 |
| 5 | Москвич 412 , ГАЗ (Волга), Нива, Шевроле-Нива 700 | 600 | 1200 |
| 6 | Alfa Romeo | 800 | 1600 |
| 7 | Audi 80, В4, 100, 200 | 800 | 1600 |
| 8 | Audi A3, А4, A6, | 900 | 1800 |
| 9 | A6 Quattro, TT, S8, Q3, All Road, Q5 | 950 | 1900 |
| 10 | Audi Q7, Audi A8, Audi A8 Quattro, S8 Quattro | 1100 | 2200 |
| 11 | BMW 3 серии | 900 | 1800 |
| 12 | BMW 5 серии, X3, X4 | 900 | 1800 |
| 13 | BMW 7 серии, X5, X6, M6 | 1100 | 2200 |
| 14 | Cadillac DeVille, Escalade | 1100 | 2200 |
| 15 | Chevrolet Blazer | 950 | 1900 |
| 16 | Chevrolet Lacetti, Epica, Spark, Aveo, Cruze Cobalt, Evanda, Lanos,Rezzo | 600 | 1200 |
| 17 | Chevrolet Lumina, Tahoe | 1100 | 2200 |
| 18 | Chevrolet PT Cruiser, Neon, 300 M | 950 | 1900 |
| 19 | CITROEN C2, С3, С4, Xsara, Picasso, Berlingo | 700 | 1400 |
| 20 | CITROEN C5, Xsantia | 900 | 1800 |
| 21 | CITROEN Jumper | 900 | 1800 |
| 22 | Daewoo Matiz | 600 | 1200 |
| 23 | Daewoo Nexia, Lanos, Espero, Kalos, Magnus, Nubira | 700 | 1400 |
| 24 | Daewoo, Leganza, Musso | 800 | 1600 |
| 25 | Dodge Caravan, Neon | 800 | 1600 |
| 26 | FAW Vito | 700 | 1400 |
| 27 | Fiat Albea, Doblo, Punto, Panda, Bravo | 700 | 1400 |
| 28 | Fiat Ducato | 1000 | 2000 |
| 29 | Ford Ka, Escort, Fiesta, Orion, Fusion | 600 | 1200 |
| 30 | Ford Focus | 700 | 1400 |
| 31 | Ford Mondeo, Cougar, C-Max, Scorpio* | 800 | 1600 |
| 32 | Ford Taurus, Thunderbird, Probe, Tranzit, Galaxy | 950 | 1900 |
| 33 | Ford Explorer, Bronco, Maverick, Galaxy | 1050 | 2100 |
| 34 | Haval H7 | 800 | 1600 |
| 35 | Haval Dargo, Haval Jolion | 900 | 1800 |
| 36 | Haval H9 | 1000 | 2000 |
| 37 | Ford Expedition, Excursion | 1100 | 2200 |
| 38 | Honda Civic, Capa, Logo | 700 | 1400 |
| 39 | Honda Accord, Prelude, Integra | 800 | 1600 |
| 40 |
Honda CR-V. HRV, Shuttle, GRETTA HRV, Shuttle, GRETTA
|
1900 | |
| 41 | Hyndai Pony, Getz, Solaris, Accent, Verna, I20, | 600 | 1200 |
| 42 | Lantra , I30 | 700 | 1400 |
| 43 | Hyndai Sonata. NF, I40, Elantra | 800 | 1600 |
| 44 | Hyndai Galloper. Tucsan. Santa Fe, Grandeur | 950 | 1900 |
| 45 | Hyndai Starex, H 1, Creta | 900 | 1800 |
| 46 | Isuzu Trooper, Gemini | 750 | 1500 |
| 47 | Jaguar F-TYPE, I-PACE, XE, XK, XKR, XKR-S, X-TYPE | 1000 | 2000 |
| 48 | Jaguar XF, XJ, XFR-S, XFR, F-TYPE, E-PACE | 1100 | 2200 |
| 49 | Jaguar F-PACE | 1100 | 2200 |
| 50 | Jeep Grand Cherokee, Caliber, Wrangler | 1000 | 2000 |
| 51 | Kia Rio, Avella, Picanto, Soul | 600 | 1200 |
| 52 | Kia Sephia, Shuma, Cerato, Ceed | 700 | 1400 |
| 53 | Kia Clarus, Credos*, Sephia II, Spectra, Optima | 800 | 1600 |
| 54 | Kia Magentis, Sportage, Carnival,Seltos | 800 | 1600 |
| 55 | Kia Sorento | 900 | 1800 |
| 56 | Land Rover | 1000 | 2000 |
| 57 | Lexus 1S 200, 1S 300 | 900 | 1800 |
| 58 | Lexus GS 300, GS 400, LS 400 | 950 | 1900 |
| 59 | Lexus RX 300, 350, 450 | 1050 | 2100 |
| 60 | Lexus LX 470, 570 | 1100 | 2200 |
| 61 | Mazda Demio, Capella, Premacy | 600 | 1200 |
| 62 | Mazda 6, mx-3, mx-5, MPV, 3, 323,626 | 700 | 1400 |
| 63 | Mazda CX-5,CX-7 | 900 | 1800 |
| 64 | Mazda CX-9 | 1000 | 2000 |
| 65 | MB А серии | 800 | 1600 |
| 66 | MB С серии | 900 | 1800 |
| 67 | MB E серии, Sprinter | 1000 | 2000 |
| 68 | MB S, ML, V серий | 1100 | 2200 |
| 69 | MB G, GL серии | 1200 | 2400 |
| 70 | Mitsubishi Colt, Space Star | 600 | 1200 |
| 71 | Mitsubishi Galant, Carisma, Legnum, Eclips, Lancer | 700 | 1400 |
| 72 | Mitsubishi Chariot, Grandis, Outlander | 800 | 1600 |
| 73 | Mitsubishi L 200, Delica, Space Gear | 900 | 1800 |
| 74 | Mitsubishi Pajero, Montero, RVR, Space Runner/Wagon | 1000 | 2000 |
| 75 | Nissan Micra, Almera, Primera, Sunny, Pulsar, Cube, Tiida, Note | 600 | 1200 |
| 76 | Nissan Maxima, Cefiro, Teana, X-Trail, Juke | 900 | 1800 |
| 77 | Nissan Pathfinder | 1000 | 2000 |
| 78 | Nissan, Serena, Qashqai, Terrano | 900 | 1800 |
| 79 | Opel Corsa, Astra, Combo, Kadet | 600 | 1200 |
| 80 | Opel Omega, Tigra, Zafira, Vectra, Kaddy, meriva | 700 | 1400 |
| 81 | Opel Frontera, Monterey | 900 | 1800 |
| 82 | Pontiac | 900 | 1800 |
| 83 |
Peugeot 106. 206,306,307, 308, Partner 206,306,307, 308, Partner
|
600 | 1200 |
| 84 | Peugeot 405, 406, 605, 407 | 700 | 1400 |
| 85 | Peugeot 607, 806, Boxter | 1000 | 2000 |
| 86 | Renault Clio, Simbol*, Logan, Twingoo, Kangoo, Sandero | 600 | 1200 |
| 87 | Renault Laguna, Safran, Scenic, Megane, Fluence | 700 | 1400 |
| 88 | Renault Duster | 800 | 1600 |
| 89 | Range Rover | 1050 | 2100 |
| 90 |
Saab 900. 9000, 9-3, 9-5 9000, 9-3, 9-5
|
700 | 1400 |
| 91 | Seat Arosa, Ibiza, Toledo, Leon, Cordoba | 600 | 1200 |
| 92 | Seat Alhambra | 700 | 1400 |
| 93 | Skoda Fabia, Felicia | 600 | 1200 |
| 94 | Skoda Octavia I/II/III, Romster, Yeti | 700 | 1400 |
| 95 | Skoda Octavia 4×4, SuperВ | 800 | 1600 |
| 96 | Skoda Karoq | 900 | 1800 |
| 97 | Skoda Kodiak | 1000 | 2000 |
| 98 | Subaru Impreza, Forester, Legacy | 800 | 1600 |
| 99 | Subaru Outback | 800 | 1600 |
| 100 | Suzuki Vitara, Grand Vitara | 800 | 1600 |
| 101 | SsangYong Kyron, Actyon | 800 | 1600 |
| 102 | SsangYong Rexton | 900 | 1800 |
| 103 | Toyota Corolla, Carina, Sprinter, Vitz, Corsa*,Yaris, Auris, Prius, Picnic | 600 | 1200 |
| 104 | Toyota Vista, Avensis | 800 | 1600 |
| 105 | Toyota Previa, Camry, RAV 4, Crown, Celica, Mark II, h2 | 850 | 1700 |
| 106 | Toyota Land Cruiser Prado, Harrier | 1100 | 2200 |
| 107 | VW Polo, Lupo | 600 | 1200 |
| 108 | VW Golf V, VI, VII, VIII | 700 | 1400 |
| 109 | VW Tiguan, Amarok | 1000 | 2000 |
| 110 | VW Vento, Bora, Jetta | 700 | 1400 |
| 111 | VW Touareg | 1100 | 2200 |
| 112 | VW Passat B4, B5 | 700 | 1400 |
| 113 | VW Passat B6, B7, B8, СС | 800 | 1600 |
| 114 | VW Transporter, Sharan, Multivan, Каравелла | 900 | 1800 |
| 115 | VW Taos | 1000 | 2000 |
| 116 | VW Teramont | 1150 | 2300 |
| 117 | Volvo S40/V40, C30 | 700 | 1400 |
| 118 | Volvo S60, 850 | 800 | 1600 |
| 119 | Volvo S80, XC60 | 900 | 1800 |
| 120 | Volvo Cross Country, XC90 | 1000 | 2000 |
* — автомобили, оснащенные полным приводом Китайские автомобили: цена по факту от 1200 в зависимости от класса авто (по аналогам)!!
Режимы отказаGAN: как их идентифицировать и контролировать
Генеративно-состязательная сеть представляет собой комбинацию двух подсетей, которые конкурируют друг с другом во время обучения, чтобы генерировать реалистичные данные.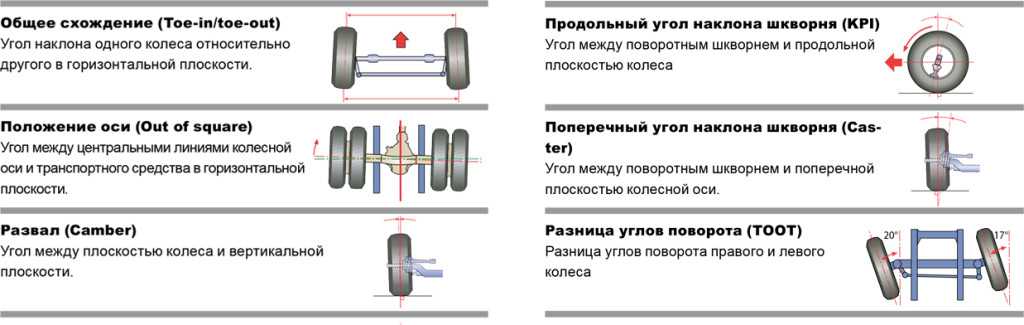 Генераторная сеть генерирует подлинные искусственные данные, в то время как Дискриминаторная сеть определяет, являются ли данные искусственными или реальными.
Генераторная сеть генерирует подлинные искусственные данные, в то время как Дискриминаторная сеть определяет, являются ли данные искусственными или реальными.
Хотя GAN являются мощными моделями, их довольно сложно обучить. Мы обучаем Генератор и Дискриминатор одновременно, за счет друг друга. Это динамическая система, в которой, как только параметры одной модели обновляются, меняется характер задачи оптимизации, и из-за этого достижение сходимости может быть затруднено.
Обучение также может привести к сбою GAN при моделировании полного распределения, и это также называется Сбой режима .
В этой статье:
- мы увидим, как обучить стабильную модель GAN
- , а затем поиграем с процессом обучения, чтобы понять возможные причины сбоев режима.
Я тренировал GAN в течение последних нескольких лет и заметил, что обычные режимы отказа в GAN — Mode Collapse и Convergence Failure , о которых мы поговорим в этой статье.
Обучение стабильной сети GAN
Чтобы понять, как может произойти сбой (при обучении GAN), давайте сначала обучим стабильную сеть GAN. Мы будем использовать набор данных MNIST, нашей целью будет создание искусственных рукописных цифр из случайного шума с использованием сети генератора.
Генератор будет принимать на вход случайный шум, а на выходе будут фальшивые рукописные цифры размером 28×28. Дискриминатор будет принимать входные изображения 28 × 28 как от генератора, так и от наземной правды, и попытается правильно их классифицировать.
Я взял скорость обучения 0,0002 для оптимизатора Адама и 0,5 в качестве импульса для оптимизатора Адама.
Давайте посмотрим на код нашей стабильной сети GAN. Во-первых, давайте сделаем необходимый импорт.
импортная горелка импортировать torch.nn как nn импортировать torchvision.transforms как преобразования импортировать torch.optim как optim импортировать torchvision.datasets как наборы данных импортировать numpy как np из torchvision.utils импортировать make_grid из torch.utils.data импортировать DataLoader из tqdm импортировать tqdm импортировать neptune.new как neptune из файла импорта neptune.new.types
 utils импортировать make_grid
из torch.utils.data импортировать DataLoader
из tqdm импортировать tqdm
импортировать neptune.new как neptune
из файла импорта neptune.new.types
utils импортировать make_grid
из torch.utils.data импортировать DataLoader
из tqdm импортировать tqdm
импортировать neptune.new как neptune
из файла импорта neptune.new.types Обратите внимание, что в этом упражнении мы будем использовать PyTorch для обучения нашей модели и панель инструментов neptune.ai для отслеживания экспериментов. Вот ссылка на все мои эксперименты. Я запускал сценарии в colab, и Neptune упростил отслеживание всех экспериментов.
Правильное отслеживание эксперимента в этом случае действительно важно, потому что графики потерь и промежуточные изображения могут очень помочь определить, есть ли режим отказа. В качестве альтернативы вы можете использовать matplotlib, священный, TensorBoard и т. д., в зависимости от вашего варианта использования и комфорта.
Сначала мы инициализируем запуск Neptune. Вы можете получить путь к проекту и токен API после создания проекта на панели инструментов Neptune.
запуск = neptune.init( проект="имя проекта", api_token="Ваш токен API", )
Мы сохраняем размер партии 1024 и будем работать в течение 100 эпох. Скрытое измерение инициализируется для генерации случайных данных для ввода генератора. И размер выборки будет использоваться для вывода 64 изображений в каждую эпоху, чтобы мы могли визуализировать качество изображений после каждой эпохи. k — количество шагов, для которых мы собираемся запускать дискриминатор.
Скрытое измерение инициализируется для генерации случайных данных для ввода генератора. И размер выборки будет использоваться для вывода 64 изображений в каждую эпоху, чтобы мы могли визуализировать качество изображений после каждой эпохи. k — количество шагов, для которых мы собираемся запускать дискриминатор.
размер_пакета = 1024
эпохи = 100
размер_образца = 64
скрытый_дим = 128
к = 1
устройство = torch.device('cuda', если torch.cuda.is_available() иначе 'процессор')
преобразование = преобразование.Составить([
преобразовывает.ToTensor(),
преобразовывает. Нормализовать ((0,5,), (0,5,)),
])
Теперь мы загружаем данные MNIST и создаем объект Dataloader.
train_data = наборы данных.MNIST( корень='../ввод/данные', поезд = правда, скачать = Верно, трансформировать = трансформировать ) train_loader = DataLoader (train_data, batch_size=batch_size, shuffle=True)
Наконец, мы определяем некоторые гиперпараметры для обучения и передаем их на панель инструментов Neptune с помощью объекта запуска.
параметров = {"learning_rate": 0,0002,
"оптимизатор": "Адам",
"оптимизатор_бетас": (0,5, 0,999),
"латентный_дим": латентный_дим}
run["parameters"] = params Здесь мы определяем сети генератора и дискриминатора.
Генераторная сеть
- Генераторная модель использует в качестве входных данных скрытое пространство, которое является случайным шумом.
- В первом слое мы меняем скрытое пространство (размерность 128) на функциональное пространство из 128 каналов и каждого канала высотой и шириной 7×7.
- После двух слоев деконволюции увеличьте высоту и ширину нашего пространства признаков.
- Затем следует слой свертки с активацией tanh для создания изображения с одним каналом и высотой и шириной 28×28.
генератор класса (nn.Module):
def __init__(я, скрытое_пространство):
супер(Генератор, сам).__init__()
self.latent_space = скрытое_пространство
self.fcn = nn. Sequential(
nn.Linear(in_features=self.latent_space, out_features=128*7*7),
nn.LeakyReLU(0.2),
)
self.deconv = nn.Sequential(
nn.ConvTranspose2d (in_channels = 128, out_channels = 128, kernel_size = (4, 4), stride = (2, 2), padding = (1, 1)),
nn.LeakyReLU(0.2),
nn.ConvTranspose2d (in_channels = 128, out_channels = 128, kernel_size = (4, 4), stride = (2, 2), padding = (1, 1)),
nn.LeakyReLU(0.2),
nn.Conv2d (in_channels = 128, out_channels = 1, kernel_size = (3, 3), padding = (1, 1)),
nn.Tanh()
)
защита вперед (я, х):
х = self.fcn(x)
х = х.вид (-1, 128, 7, 7)
х = саморазвитие (х)
возврат х  Sequential(
nn.Linear(in_features=self.latent_space, out_features=128*7*7),
nn.LeakyReLU(0.2),
)
self.deconv = nn.Sequential(
nn.ConvTranspose2d (in_channels = 128, out_channels = 128, kernel_size = (4, 4), stride = (2, 2), padding = (1, 1)),
nn.LeakyReLU(0.2),
nn.ConvTranspose2d (in_channels = 128, out_channels = 128, kernel_size = (4, 4), stride = (2, 2), padding = (1, 1)),
nn.LeakyReLU(0.2),
nn.Conv2d (in_channels = 128, out_channels = 1, kernel_size = (3, 3), padding = (1, 1)),
nn.Tanh()
)
защита вперед (я, х):
х = self.fcn(x)
х = х.вид (-1, 128, 7, 7)
х = саморазвитие (х)
возврат х
Sequential(
nn.Linear(in_features=self.latent_space, out_features=128*7*7),
nn.LeakyReLU(0.2),
)
self.deconv = nn.Sequential(
nn.ConvTranspose2d (in_channels = 128, out_channels = 128, kernel_size = (4, 4), stride = (2, 2), padding = (1, 1)),
nn.LeakyReLU(0.2),
nn.ConvTranspose2d (in_channels = 128, out_channels = 128, kernel_size = (4, 4), stride = (2, 2), padding = (1, 1)),
nn.LeakyReLU(0.2),
nn.Conv2d (in_channels = 128, out_channels = 1, kernel_size = (3, 3), padding = (1, 1)),
nn.Tanh()
)
защита вперед (я, х):
х = self.fcn(x)
х = х.вид (-1, 128, 7, 7)
х = саморазвитие (х)
возврат х См. также
️ 6 архитектур GAN, которые вы действительно должны знать
Сеть дискриминатора
- Наша сеть дискриминатора состоит из двух сверточных слоев для генерации признаков из изображения, поступающего от генератора, и реальных изображений.
- За ним следует слой классификатора, который классифицирует, является ли изображение предсказанным дискриминатором реальным или поддельным.

Дискриминатор класса (nn.Module):
защита __init__(сам):
супер(Дискриминатор, я).__init__()
self.conv = nn.Sequential(
nn.Conv2d (in_channels = 1, out_channels = 64, kernel_size = (4, 4), шаг = (2, 2), заполнение = (1, 1)),
nn.LeakyReLU(0.2),
nn.Conv2d (in_channels = 64, out_channels = 64, kernel_size = (4, 4), шаг = (2, 2), заполнение = (1, 1)),
nn.LeakyReLU(0.2)
)
self.classifier = nn.Sequential(
nn.Linear(in_features=3136, out_features=1),
nn.Сигмоид()
)
защита вперед (я, х):
х = самоутверждение (х)
х = х.вид (х.размер (0), -1)
х = самоклассификатор (х)
возврат х Теперь мы инициализируем сеть генератора и дискриминатора, а также оптимизаторы и функцию потерь.
И у нас есть несколько вспомогательных функций для создания меток для поддельных и реальных изображений (где size — это размер пакета) и функция create_noise для ввода генератора.
генератор = Генератор (latent_dim).to (устройство) дискриминатор = дискриминатор().к(устройство) optim_g = optim.Adam (параметры генератора (), lr = 0,0002, бета = (0,5, 0,999)) optim_d = optim.Adam (дискриминатор. параметры (), lr = 0,0002, бета = (0,5, 0,999)) критерий = nn.BCELoss() def label_real (размер): labels = torch.ones(размер, 1) вернуть labels.to(устройство) определение label_fake (размер): labels = torch.zeros(размер, 1) вернуть labels.to(устройство) def create_noise (sample_size, hidden_dim): return torch.randn(sample_size, hidden_dim).to(device)
Функция обучения генератора
Теперь мы обучим генератор:
- Генератор принимает случайный шум и выдает поддельные изображения.
- Эти поддельные изображения затем отправляются в дискриминатор, и теперь мы минимизируем потери между реальной меткой и предсказанием дискриминатора поддельного изображения.
- Из этой функции мы будем наблюдать за потерями генератора.
def train_generator (оптимизатор, data_fake): b_size = data_fake.size (0) реальная_метка = реальная_метка(b_size) оптимизатор.zero_grad() вывод = дискриминатор (data_fake) потеря = критерий (выход, реальная_метка) потеря.назад() оптимизатор.шаг() обратная потеря
Функция обучения дискриминатора
Мы создаем функцию train_discriminator:
- Эта сеть, как мы знаем, получает входные данные от наземной истины (т.е. реальных изображений) и генераторной сети (т.е. поддельных изображений) во время обучения.
- Одно за другим мы передаем поддельное и реальное изображение, вычисляем потери и выполняем обратное распространение. Мы будем наблюдать две потери дискриминатора; потери на реальных изображениях (loss_real) и потери на поддельных изображениях (loss_fake).
def train_distributor (оптимизатор, data_real, data_fake): b_size = data_real.size (0) реальная_метка = реальная_метка(b_size) поддельная_метка = метка_поддельная (b_size) оптимизатор.
 zero_grad()
output_real = дискриминатор (data_real)
loss_real = критерий (output_real, real_label)
output_fake = дискриминатор (data_fake)
loss_fake = критерий (output_fake, fake_label)
loss_real.backward()
loss_fake.backward()
оптимизатор.шаг()
возврат loss_real, loss_fake
zero_grad()
output_real = дискриминатор (data_real)
loss_real = критерий (output_real, real_label)
output_fake = дискриминатор (data_fake)
loss_fake = критерий (output_fake, fake_label)
loss_real.backward()
loss_fake.backward()
оптимизатор.шаг()
возврат loss_real, loss_fake Обучение модели GAN
Теперь, когда у нас есть все функции, давайте обучим нашу модель и посмотрим на наблюдения, чтобы определить, стабильно ли обучение или нет.
- Шум в первой строке будет использоваться для вывода промежуточных изображений после каждой эпохи. Мы сохраняем шум одинаковым, чтобы мы могли сравнивать изображения в разные эпохи.
- Теперь для каждой эпохи мы обучаем дискриминатор k раз (один раз в данном случае при k=1), за каждый раз обучается генератор.
- Все потери регистрируются и отправляются на панель управления Neptune для построения графика. Нам не нужно добавлять их в список, используя панель инструментов Neptune, мы можем строить графики потерь на лету. Он также будет записывать потери на каждом этапе в файле .csv.
- Я сохранил сгенерированные изображения после каждой эпохи в метаданных Neptune, используя функцию [dot]upload.
 Он также будет записывать потери на каждом этапе в файле .csv.
Он также будет записывать потери на каждом этапе в файле .csv. шум = создать_шум (размер выборки, скрытый_тусклый)
генератор.поезд()
дискриминатор.train()
для эпохи в диапазоне (эпохи):
потеря_г = 0,0
loss_d_real = 0,0
loss_d_fake = 0,0
# обучение
для bi данные в tqdm(enumerate(train_loader), total=int(len(train_data)/train_loader.batch_size)):
изображение, _ = данные
изображение = изображение.на(устройство)
b_size = длина (изображение)
для шага в диапазоне (k):
data_fake = генератор (создать_шум (b_size, скрытый_дим)). отсоединить ()
data_real = изображение
loss_d_fake_real = train_distributor (optim_d, data_real, data_fake)
loss_d_real += loss_d_fake_real[0]
loss_d_fake += loss_d_fake_real[1]
data_fake = генератор (создать_шум (b_size, скрытый_дим))
loss_g += train_generator(optim_g, data_fake)
# вывод и наблюдения
сгенерированный_img = генератор (шум). процессор (). отсоединить ()
сгенерированный_img = make_grid (сгенерированный_img)
сгенерированный_img = np.moveaxis (сгенерированный_img.numpy (), 0, -1)
run[f'generated_img/{эпоха}'].upload(File.as_image(generated_img))
epoch_loss_g = loss_g / би
epoch_loss_d_real = loss_d_real/bi
epoch_loss_d_fake = loss_d_fake/би
run["train/loss_generator"].log(epoch_loss_g)
run["поезд/убыток_дискриминатор_реальный"].log(epoch_loss_d_real)
run["поезд/потеря_дискриминатора_фальшивка"].log(epoch_loss_d_fake)
print(f"Эпоха {эпоха} из {эпох}")
print(f"Потеря генератора: {epoch_loss_g:.8f}, Ложная потеря дискриминатора: {epoch_loss_d_fake:.8f}, Реальная потеря дискриминатора: {epoch_loss_d_real:.8f}")  процессор (). отсоединить ()
сгенерированный_img = make_grid (сгенерированный_img)
сгенерированный_img = np.moveaxis (сгенерированный_img.numpy (), 0, -1)
run[f'generated_img/{эпоха}'].upload(File.as_image(generated_img))
epoch_loss_g = loss_g / би
epoch_loss_d_real = loss_d_real/bi
epoch_loss_d_fake = loss_d_fake/би
run["train/loss_generator"].log(epoch_loss_g)
run["поезд/убыток_дискриминатор_реальный"].log(epoch_loss_d_real)
run["поезд/потеря_дискриминатора_фальшивка"].log(epoch_loss_d_fake)
print(f"Эпоха {эпоха} из {эпох}")
print(f"Потеря генератора: {epoch_loss_g:.8f}, Ложная потеря дискриминатора: {epoch_loss_d_fake:.8f}, Реальная потеря дискриминатора: {epoch_loss_d_real:.8f}")
процессор (). отсоединить ()
сгенерированный_img = make_grid (сгенерированный_img)
сгенерированный_img = np.moveaxis (сгенерированный_img.numpy (), 0, -1)
run[f'generated_img/{эпоха}'].upload(File.as_image(generated_img))
epoch_loss_g = loss_g / би
epoch_loss_d_real = loss_d_real/bi
epoch_loss_d_fake = loss_d_fake/би
run["train/loss_generator"].log(epoch_loss_g)
run["поезд/убыток_дискриминатор_реальный"].log(epoch_loss_d_real)
run["поезд/потеря_дискриминатора_фальшивка"].log(epoch_loss_d_fake)
print(f"Эпоха {эпоха} из {эпох}")
print(f"Потеря генератора: {epoch_loss_g:.8f}, Ложная потеря дискриминатора: {epoch_loss_d_fake:.8f}, Реальная потеря дискриминатора: {epoch_loss_d_real:.8f}") Давайте посмотрим на промежуточные изображения.
Эпоха 10
Рис. 1 – Цифры, сгенерированные стабильной GAN на 10-й эпохе | Источник: АвторЭто 64 цифры, сгенерированные в 10-ю эпоху.
Эпоха 100
Рис. Источник: Автор Они созданы с использованием того же шума в эпоху 100. Они выглядят намного лучше, чем изображения в эпоху 10, здесь мы действительно можем идентифицировать разные цифры. Мы можем обучаться еще большему количеству эпох или настраивать гиперпараметры для лучшего качества изображений.
Они выглядят намного лучше, чем изображения в эпоху 10, здесь мы действительно можем идентифицировать разные цифры. Мы можем обучаться еще большему количеству эпох или настраивать гиперпараметры для лучшего качества изображений.
Графики убытков
Вы можете легко перейти в «Добавить новую панель мониторинга» на панели инструментов Neptune и объединить различные графики потерь в один.
Рис. 3 – График потерь, три линии показывают потери для генератора, поддельные изображения на дискриминаторе и реальные изображения на дискриминаторе | Источник На рис. 3 вы можете наблюдать стабилизацию потерь после эпохи 40. Потери дискриминатора для реального и поддельного изображений остаются около 0,6, тогда как для генератора они составляют около 0,8. Приведенный выше график является ожидаемым графиком для стабильной тренировки. Мы можем рассматривать это как базовый уровень и экспериментировать с изменением k (шаги обучения для дискриминатора), увеличением количества эпох и т. д.
д.
Теперь, когда мы построили стабильную модель GAN, давайте посмотрим на режимы отказа.
Связанные
️ Понимание функций потерь GAN
Режимы отказа GAN
В последние годы мы наблюдаем быстрый рост приложений GAN, будь то повышение разрешения изображений, генерация по условию или генерация синтетических данных, подобных реальным.
Неудача в обучении является серьезной проблемой для таких приложений.
Как определить режимы отказа GAN? Как узнать, есть ли режим сбоя:
- В идеале генератор должен выдавать разнообразные данные. Если он производит один вид или аналогичный набор выходных данных, это Mode Collapse .
- Когда генерируются визуально неверные наборы данных, это может быть случаем Ошибка конвергенции .
Что вызывает сбой режима в GAN? Причины отказов:
- Невозможно найти конвергенцию для сетей.
- Генератор может найти данные определенного типа, которые могут легко обмануть дискриминатор. Он будет снова и снова генерировать одни и те же данные, предполагая, что цель достигнута. Вся система может переоптимизировать этот единственный тип вывода.

Проблема с определением сбоя режима и других режимов отказа заключается в том, что мы не можем полагаться на качественный анализ (например, просмотр данных вручную). Этот метод может дать сбой, если имеется огромное количество данных или если проблема действительно сложна (мы не всегда будем генерировать цифры).
Оценка режимов отказа
В этом разделе мы попытаемся понять, как определить, имеет ли место сбой режима или сбой конвергенции. Мы увидим три метода оценки. Один из них мы уже обсуждали в предыдущем разделе.
Глядя на промежуточные изображения
Давайте посмотрим несколько примеров, где по промежуточным изображениям можно оценить режим коллапса и конвергенции. На рис. 4 мы видим изображения действительно плохого качества, а на рис. 5 мы видим тот же набор сгенерированных изображений.
5 мы видим тот же набор сгенерированных изображений.
Хотя на рис. 4 показан пример сбоя сходимости, на рис. 5 показан сбой режима. Вы можете получить представление о том, как работает ваша модель, просмотрев изображения вручную. Но когда сложность проблемы высока или данные для обучения слишком велики, вы не сможете идентифицировать коллапс режима.
Давайте рассмотрим несколько лучших методов.
Наблюдая за графиками потерь
Мы можем многое узнать о том, что происходит, глядя на графики потерь. Например, на рис. 3 вы можете заметить, что потери насыщаются после определенного момента, демонстрируя ожидаемое поведение. Теперь давайте посмотрим на этот график потерь на рис. 6, где я уменьшил скрытое измерение, поэтому поведение неустойчиво.
Теперь давайте посмотрим на этот график потерь на рис. 6, где я уменьшил скрытое измерение, поэтому поведение неустойчиво.
Как видно на рис. 6, потери генератора колеблются между 1 и 1,2. Хотя потери дискриминатора для поддельных и реальных изображений также колеблются около 0,6, потери несколько больше, чем мы заметили в стабильной версии.
Я бы посоветовал, даже если график имеет высокую дисперсию, это нормально. Вы можете увеличить количество эпох и подождать еще некоторое время, пока оно не станет стабильным, и, самое главное, продолжать проверять сгенерированные промежуточные изображения.
Если график потерь падает до нуля в начальные эпохи как для генератора, так и для дискриминатора, то это тоже проблема. Это означает, что генератор нашел набор поддельных изображений, которые действительно легко идентифицировать дискриминатору.
Количество статистически различных интервалов (показатель NDB)
В отличие от двух вышеупомянутых качественных методов, оценка NDB является количественным методом. Таким образом, вместо того, чтобы просматривать изображения и графики потерь и что-то упускать или делать неправильную интерпретацию, оценка NDB может определить, есть ли сбой режима.
Таким образом, вместо того, чтобы просматривать изображения и графики потерь и что-то упускать или делать неправильную интерпретацию, оценка NDB может определить, есть ли сбой режима.
Давайте разберемся, как работает оценка NDB:
- У нас есть два набора, обучающий набор (на котором обучается модель) и тестовый набор (фальшивые изображения, сгенерированные генератором на случайном шуме после обучения).
- Теперь разделите обучающую выборку на K кластеров, используя кластеризацию K-средних. Это будут наши K разных бункеров.
- Теперь распределите тестовые данные по этим K интервалам на основе евклидова расстояния между точками тестовых данных и центроидами K кластеров.
- Теперь проведите тест с двумя выборками между обучающей и тестовой выборками для каждого бина и рассчитайте Z-показатель. Если Z-оценка меньше порогового значения (в статье используется 0,05), пометьте ячейку как статистически отличающуюся.
- Подсчитайте количество статистически различных интервалов и разделите их на К.
- Полученное значение должно находиться в диапазоне от 0 до 1.

Большое количество статистически различных бинов означает, что значение ближе к 1, означает коллапс высокой моды, означает плохую модель. Тем не менее, оценка NDB, приближающаяся к 0, означает меньшее коллапс режима или его отсутствие.
Метод оценки NDB взят из статьи О GAN и GMM.
Рис. 7 — (a) Вверху слева — изображение из набора обучающих данных (b) Внизу слева — изображение из набора тестовых данных и показано перекрытие (c) Гистограмма, показывающая бины для обучающего и тестового набора | ИсточникОчень хорошо реализованный код для расчета NDB можно найти в этом блокноте совместной работы Кевина Шена.
Решение режимов отказа
Теперь, когда у нас есть понимание того, как выявлять проблемы при обучении GAN, мы рассмотрим некоторые решения и эмпирические правила для их решения. Некоторые из них будут базовыми настройками гиперпараметров. Мы обсудим некоторые алгоритмы, если вы хотите сделать все возможное, чтобы стабилизировать свои GAN.
Функции стоимости
Есть документы, в которых говорится, что ни одна функция потерь не превосходит других. Я бы посоветовал вам начать с более простых функций потерь, таких как мы используем бинарную кросс-энтропию, и подняться оттуда.
Теперь нет необходимости использовать определенные функции потерь с определенными архитектурами GAN. Но для написания этих статей было проведено много исследований, многие из которых все еще активны. Таким образом, было бы хорошей практикой использовать эти функции потерь на рис. 8, которые могут помочь вам предотвратить как коллапс моды, так и конвергенцию.
Рис. 8 – Архитектура GAN и соответствующие функции потерь, использованные в статьях | Источник Поэкспериментируйте с различными функциями потерь и обратите внимание, что ваша функция потерь может дать сбой из-за неправильной настройки гиперпараметров, например слишком агрессивного оптимизатора или большой скорости обучения. Мы поговорим об этих проблемах позже.
Скрытое пространство
Скрытое пространство — это место, откуда берется входной сигнал для генератора (случайный шум). Теперь, если вы ограничите скрытое пространство, оно будет производить больше выходных данных того же типа, что видно из рис. 9. Вы также можете посмотреть на соответствующий график потерь на рис. 6.
Рис. пространство 2 | Источник: АвторНа рис. 9 вы видите столько одинаковых восьмерок и семерок? Отсюда и коллапс режима.
Рис. 10. Здесь я указал скрытое пространство как 1, пробежал 200 эпох.Мы видим, что потери генератора постоянно увеличиваются, а все потери колеблются | Источник Рис. 11 – Подучасток, соответствующий рис. 10, где скрытое пространство равно 1.
Эти цифры генерируются на 200-й эпохе | Источник: Автор
Обратите внимание, что при обучении сети GAN очень важно предоставить достаточное количество скрытого пространства, чтобы генератор мог создавать различные функции.
Скорость обучения
Одна из наиболее распространенных проблем, с которыми я столкнулся при обучении GAN, — это высокая скорость обучения. Это приводит либо к коллапсу мод, либо к неконвергенции. Очень важно, чтобы вы поддерживали скорость обучения на низком уровне, всего 0,0002 или даже ниже.
Рис. 12 – Значения потерь при скорости обучения 0,2 | Источник Рис. 13 — Сгенерированные изображения на 100-й эпохе со скоростью обучения 0,2 | Источник: АвторИз графика потерь на рис. 12 ясно видно, что дискриминатор идентифицирует все изображения как реальные. Вот почему потери для поддельных изображений высоки, а для реальных изображений нет. Теперь генератор предполагает, что все созданные им изображения обманывают дискриминатор. Проблема здесь в том, что дискриминатор даже немного не обучается из-за такой высокой скорости обучения.
Чем выше размер пакета, тем выше может быть значение скорости обучения, но всегда старайтесь быть на более безопасной стороне.
Оптимизатор
Агрессивный модификатор — плохая новость для обучения GAN. Это приводит к невозможности найти равновесие между потерями генератора и потерями дискриминатора и, следовательно, сбоем сходимости.
Рис. 14 – График потерь со значениями по умолчанию для Adam Optimizer (бета 0,9 и 0,999) | ИсточникВ Adam Optimizer бета — это гиперпараметры, используемые для расчета скользящего среднего значения градиента и его квадрата. Мы изначально (в стабильном обучении) использовали значение 0,5 для бета1. Меняем на 0.9(значение по умолчанию) увеличивает агрессивность оптимизатора.
На рис. 14 дискриминатор работает хорошо. Поскольку потери генератора увеличиваются, мы можем сказать, что он создает такие плохие изображения, что дискриминатору очень легко классифицировать их как поддельные. График потерь не достигает равновесия.
Сопоставление признаков
Сопоставление признаков предлагает новую целевую функцию, где мы не используем напрямую выходные данные дискриминатора. Генератор обучен таким образом, что ожидается, что выходные данные генератора будут соответствовать значениям реальных изображений на промежуточных признаках дискриминатора.
Для реального изображения и фальшивого изображения векторы признаков (f(x) на рис. 15) вычисляются на промежуточном слое в мини-пакетах, и измеряется расстояние L2 по средним значениям этих векторов признаков.
Имеет смысл сопоставлять сгенерированные данные со статистикой реальных данных. В случае, если оптимизатор становится слишком жадным в поисках наилучшей генерации данных и никогда не достигает сходимости, сопоставление признаков может быть полезным.
Историческое усреднение
Мы сохраняем скользящее среднее значение параметров (θ) предыдущего t моделей. Теперь мы штрафуем модель, добавляя стоимость L2 к функции стоимости, используя предыдущие параметры.
Рис. 16 – Стоимость L2 | Источник Здесь θ[i] — значение параметра на i -м -м прогоне.
При работе с невыпуклыми целевыми функциями историческое усреднение может помочь сходимости модели.
Заключение
- Теперь мы понимаем важность отслеживания экспериментов при обучении GAN.
- Важно понимать графики потерь и внимательно наблюдать за генерируемыми промежуточными данными.
- Гиперпараметры, такие как скорость обучения, параметры оптимизатора, скрытое пространство и т. д., могут испортить вашу модель, если они не настроены должным образом.
- В связи с увеличением количества моделей GAN за последние несколько лет все больше и больше исследований направлено на стабилизацию обучения GAN. Есть гораздо больше методов, полезных для конкретных случаев использования.
Читать далее
- https://arxiv.org/pdf/1606.03498v1.pdf
- https://towardsdatascience.com/10-lessons-i-learned-training-generative-adversarial-networks-gans-for-a-year-c9071159628
- https://towardsdatascience.com/gan-ways-to-improve-gan-performance-acf37f9f59b
- https://arxiv. org/pdf/1805.12462.pdf
Сходимость повторных квантовых неразрушающих измерений и коллапс волновой функции — arXiv Vanity
Мишель Бауэр ♠,♣ Мишель и Денис Бернар
♣ Денис ♠ Институт теоретической физики де Сакле ифт ,
CEA-Saclay, 91191 Гиф-сюр-Иветт, Франция.
♣
Laboratoire de Physique Théorique de l’Ecole Normale Supérieure,
CNRS/ENS, Ecole Normale Supérieure, 24 rue Lhomond, 75005 Париж, Франция
1 июня 2022 г.
Abstract
Воодушевленные недавними экспериментами с квантовыми захваченными полями, мы даем строгое доказательство того, что повторяющиеся непрямые квантовые неразрушающие измерения (QND) сходятся к коллапсу волновой функции, как это предсказывается постулатами квантовой механики для прямых измерений. Мы также относим
скорость сходимости коллапсной волновой функции к относительной энтропии
каждого косвенного измерения, результат, который вступает в контакт с теорией информации.
упак:
03.65.Та, 03.65.Уд, 05.40.-а † † препринт: Препринт ИФТ 2011/??? ; архив?/???Коллапс волновой функции является основной аксиомой прямого квантового измерения а-ля фон Нейман мес . Квантовое измерение без разрушения XXX — это измерение, для которого коллапсированное состояние является собственным состоянием свободной эволюции. Повторение измерения в свернутом состоянии дает идентичные результаты, поскольку это состояние сохраняется в процессе эволюции. Косвенные измерения YYY состоит в том, чтобы позволить исследуемой квантовой системе быть запутанной с другой квантовой системой, называемой зондом, и осуществить прямое измерение на зонде. Поскольку система и зонд запутаны, вы получаете информацию. Повторение процесса запутывания и измерения статистически увеличивает объем информации, получаемой системой.
Развитие экспериментальных и теоретических знаний о процессах квантовых измерений является обязательным для развития манипулирования квантовым состоянием. Это было рано осознано Дэвис ; Hepp , что для моделирования квантовых измерений требуются системы с бесконечным числом степеней свободы, т.е. как в феноменологических стохастических моделях Гизина-Диози . Необходимость описания квантовых скачков и случайности, присущие повторным измерениям, привели к понятию квантовых траекторий DCM; Чармайкл . Параллельно инструменты открытых квантовых систем, в частности инструменты квантового стохастического исчисления HP , были адаптированы для описания квантово-континуальных измерений GBB и квантовая обратная связь Wiseman . В большинстве этих стохастических моделей движущие шумы, часто классические или квантовые броуновские движения, связаны со степенями свободы измерительного прибора.
Несмотря на сходство с этими схемами, наше доказательство коллапса волны в серии измерений QND основано на чисто квантовом описании повторяющихся взаимодействий зонд-система.
Недавно были проведены эксперименты по повторным косвенным квантовым неразрушающим измерениям, в частности, в квантовой оптике. nph). Прямые измерения в полости не выполняются. Экспериментальная цель состоит в том, чтобы восстановить начальное распределение фотонов путем накопления информации из повторных измерений эффективного спина атома. Распределение фотонов пересчитывается после каждого измерения атома по закону Байеса байес . На рис.1 показаны экспериментальные данные по эволюции восстановленных распределений фотонов. Для каждой реализации они сходятся экспериментально и численно lkb_exp к пиковым распределениям, центры которых зависят от реализации. Это коллапс.
Абстрактируем и обобщаем предыдущую ситуацию.
В начальный момент времени система находится в состоянии |φ0⟩≡|φ⟩. Это
взаимодействует в течение времени Δt с зондом, изначально находящимся в состоянии
|ψ⟩, так что пара (зонд+система) эволюционирует в U(|ψ⟩⊗|φ⟩), где U — некоторый унитарный оператор, действующий в гильбертовом пространстве Hprobe⊗Hsyst. После Δt взаимодействием системы с зондом можно пренебречь.
Тогда идеальное измерение а-ля фон Нейман
выполняется на зонде. Это означает, что существует ортонормированный базис |i⟩,
i∈I, Hprobe такой, что после измерения
(зонд+система)-состояние пропорционально
(|i⟩⟨i|⊗Id)U(|ψ⟩⊗|φ⟩)
с вероятностью ||(|i⟩⟨i|⊗Id)U(|ψ⟩⊗|φ⟩)||2. Обращение в нуль этой вероятности для определенного состояния
|i⟩ означает, что зонд не может быть найден в состоянии |i⟩, поэтому мы можем
(и должен) просто забыть о такой возможности.
Сделаем следующее предположение, связанное с несносимостью, относительно оператора эволюции U: существует ортонормированный базис |α⟩, α∈A, Hsyst и набор операторов Uα, действующих на Hprobe, таких что для каждого α
| U(|ψ⟩⊗|α⟩)=(Uα|ψ⟩)⊗|α⟩. | (1) |
Операторы Uα автоматически унитарны. Если зонд находится в состоянии |i⟩ после измерения, (вероятность ∑α∈A|⟨i|Uα|ψ⟩|2|⟨α|φ⟩|2), пара (зонд+система) снова находится в тензоре состояние продукта |i⟩⊗|φ1⟩, где
| |φ1⟩=∑α∈A⟨i|Uα|ψ⟩⟨α|φ⟩ |α⟩(∑α∈A|⟨i|Uα|ψ⟩|2|⟨α|φ⟩|2)1/ 2. | (2) |
Ясно, что мотивирующий эксперимент удовлетворяет этому свойству, если |α⟩ является основанием номера занятия Ulkb_exp .
Физика этой гипотезы такова, что окончательный
цель состоит в том, чтобы измерить наблюдаемую в системе, для которой состояния
|α⟩ собственные состояния. Как мы увидим,
это (прямое) измерение может быть (косвенно) достигнуто повторным
измерения на последовательных датчиках. Таким образом, один представляет другой зонд в систему в
состоянии |φ1⟩, пусть они взаимодействуют и после взаимодействия
измеряет зонд, чтобы получить |φ2⟩ и так далее. Обратите внимание, что в целом
на каждом шаге можно было изменить начальное состояние зонда, наблюдаемое
измеряется на щупе (именно так и происходит в мотивирующем примере),
и даже тип зондов: единственное, что нужно держать фиксированным, это
базис |α⟩, для которого выполнено свойство (1). Большинство из
следующее обсуждение может быть распространено на общую настройку mb_prep , но сохранить обозначения
просто, мы сосредоточимся на случае, когда |ψ⟩ и
базис |i⟩ одинаковы для всех зондов.
Начнем со сводки наших результатов:
i) Если проводится серия повторных косвенных измерений, состояние системы
со временем стабилизируется и дойдет до предела. Проведение идентичных независимых экспериментов
опять же, состояние системы со временем снова стабилизируется, но, возможно, с
разные лимиты.
ii) При физически значимом условии невырожденности единственно возможное
пределами состояния системы являются состояния указателя |α⟩, а
вероятность закончиться в состоянии |α⟩ начиная с состояния
|φ⟩ равно |⟨α|φ⟩|2. Отсюда и результат большого количества
повторные косвенные измерения, удовлетворяющие условию (1), подчиняются
стандартные правила квантовой механики прямые измерения.
iii) При том же условии невырожденности измерения на зондах
позволяют вывести предельное состояние указателя для каждого независимого эксперимента.
iv) Скорость сходимости к одному из состояний указателя регулируется
относительная энтропия некоторых вероятностных мер в классическом пробном пространстве.
порядка величины вероятности того, что при повторных измерениях
состояние системы приближается к состоянию указателя, но заканчивается
наконец, в другом можно вычислить явно.
Инструменты для доказательства этих утверждений взяты из классической теории случайных процессов: усиленный закон больших чисел,
мартингальная теорема о сходимости, большие уклонения. Доказательство коллапса волновой функции с использованием мартингальной теоремы о сходимости появилось в Адлере . Эти работы основаны на нелинейных стохастических расширениях уравнения Шредингера 90 363 предела 90 364, тогда как наши результаты являются чистыми следствиями квантовой механики (с измерениями на зондах) точка и ближе по духу к квантовой траектории приближается к DCM ; Charmichael и к экспериментам.
Теперь перейдем к доказательствам. Можно перефразировать уравнение (2), сказав, что для каждого α∈A
| ⟨α|φ1⟩=⟨i|Uα|ψ⟩⟨α|φ0⟩(∑α∈A|⟨i|Uα|ψ⟩|2|⟨α|φ0⟩|2)1/2 |
, если зонд находится в состоянии |i⟩. Таким образом, важным следствием (1) является отсутствие интерференционные члены для разных α, так что, взяв квадрат модуля не приводит к (значительной) потере информации. Положим p(i|α)≡|⟨i|Uα|ψ⟩|2, а q0(α)≡|⟨α|φ0⟩|2, q1(α)≡|⟨α|φ1⟩|2, q2 (α)≡|⟨α|φ2⟩|2 и так далее. Учтите, что после измерения n-й зонд имеет для каждого α∈A
| qn+1(α)=qn(α)p(i|α)∑β∈Aqn(β)p(i|β) | (3) |
с вероятностью πn(i)≡∑β∈Aqn(β)p(i|β).
Это отношение случайной рекурсии марковского типа: для вычисления
возможные значения qn+1(α) и их соответствующие вероятности, все
нужно знать, являются qn (β). Каждое измерение зонда
приводит к выбору пробных состояний |i⟩ таким, что πn(i)≠0. Вопрос, который нужно решить, это долгое время
поведения полученных случайных последовательностей qn(α).
Заметьте, что qn(α) и p(i|α) ≥0. Кроме того, ∑α∈Aqn(α)=1 и ∑i∈Ip(i|α)=1 для каждого α∈A. Отсюда следует, что ∑i∈Iπn(i)=1, как и должно быть быть. Важнейший вопрос заключается в следующем: наблюдая случайное последовательности qm(β) для m=0,⋯,n и всех β в A, что среднее значение qn+1(α)? Из (3) сразу следует, что это (условное) среднее значение, которое мы обозначаем через E(qn+1(α)|q0,⋯,qn), равно
| E(qn+1(α)|q0,⋯,qn) | = | ∑i,πn(i)≠0qn(α)p(i|α)πn(i)πn(i) | ||
| = | ∑i,πn(i)≠0qn(α)p(i|α). |
Теперь πn(i)=∑β∈Aqn(β)p(i|β) и для этого равны нулю, произведение qn(β)p(i|β) должно обращаться в нуль для всех β∈A и, в частности, для β=α, так что ∑i,πn(i)≠0qn(α)p(i|α )=∑i∈Iqn(α)p(i|α)=qn(α). Отсюда мы находим, что
| E(qn+1(α)|q0,⋯,qn)=qn(α). | (4) |
В теории случайных процессов такое свойство определяет понятие мартингал : последовательность q0,q1,⋯ является мартингалом, потому что если один знает его до времени n (т. е. если известно q0,⋯,qn), его ожидание в момент времени n+1 является его значением в момент времени n (т. е. qn). Связать квантовые меры с условными ожиданиями не так уж удивительно, потому что оба основаны на ортогональных проекциях в гильбертовых пространствах.
Имеющийся мартингейл обладает своеобразным свойством:
оно ограничено (каждое qn(α) ≥0
и ∑α∈Aqn(α)=1). Тогда мы можем привести частный случай
теорема мартингальной сходимости (см. любой современный учебник по теории вероятностей,
например martingconv , для точной формулировки):
Случайная последовательность q0,q1,⋯, являющаяся ограниченным мартингалом
сходится почти наверное и в L1. Предел, случайная величина
q∞ таков, что его математическое ожидание удовлетворяет
E(q∞)=q0.
Это глубокая теорема, и мы не знаем интуитивного аргумента. объяснить это мартин . Но в нашем случае смысл его прост. утверждение о сходимости почти наверняка является в точности математической формулировкой я). Утверждение сходимости L1 является простым следствием теоремы Лебега о мажорируемой сходимости, потому что наш мартингал ограниченный. Утверждение об математическом ожидании предельной случайной величины дает вторую часть ii) после того, как мы дали независимый аргумент для показать, что возможные пределы — это состояния указателя.
Для этого заметим, что сходимость qn(α) приводит к сходимости πn(i)=∑β∈Aqn(β)p(i|β). если я такое, что π∞(i)≠0, то для достаточно больших n πn(i)>π∞(i)/2>0, что означает, что с вероятностью 1 n-й зонд будет находиться в состоянии i для сколь угодно больших значений n. Это позволяет принимать большой предел n в (3) для этого значения i. Отсюда
| q∞(α)=q∞(α)p(i|α)∑β∈Aq∞(β)p(i|β), |
для любого i∈I такого, что π∞(i)≠0. Только α для
которые q∞(α)≠0 дают нетривиальное уравнение, поэтому мы можем ограничиться
к этим α. Затем мы можем упростить, чтобы получить p(i|α)=π∞(i)
для любого i такого, что π∞(i)≠0. Если q∞(α)≠0, то π∞(i)=0 влечет
p(i|α)=0, так что p(i|α)=π∞(i) действительно верно
для любого я. Правая часть может зависеть от i, но не зависит от
а. То же верно и для левой части: это означает, что
оператор эволюции U и зондовое измерение действуют вырожденным образом на
соответствующие кеты |α⟩. В такой дегенеративной ситуации мы не можем
ожидать измерения их по отдельности, как в стандартной квантовой мере
наблюдаемой системы, мы не можем разделить |α⟩, имеющие одинаковые
собственное значение период . Итак, мы
предположим, что для любых α,β∈A существует некоторый i∈I такой, что
p(i|α)≠p(i|β), и мы получаем, что
q∞(α)=δα,γ для некоторого γ, т.е.
возможные значения q∞(α) равны 0 или 1. Равенство
E(q∞(α))=q0(α) означает, что
q∞(α) принимает значение 1 с вероятностью
q0(α)=|⟨α|φ⟩|2 и 0 с вероятностью
1−q0(α), как и ожидалось при идеальном измерении невырожденного
наблюдаемая система с |α⟩ в качестве собственных состояний.
Доказательства утверждений iii) и iv) используют одни и те же инструменты. Начнем с определения скорость сходимости к предельному состоянию системы. Это, оказывается, зависит на это предельное состояние, и это также является ключом к утверждению iii). То, что мы до сих пор доказали, подразумевает, что в какой-то момент скажем n0, одна из компонент, скажем qn0(γ), будет большой, т.е. близко к 1, так что все остальные компоненты будут малы. Затем мы можем заменить (???) приближенной линейной рекурсией отношение, а именно, для α≠γ,
| qn+1(α)=qn(α)p(i|α)p(i|γ) | (5) |
с вероятностью p(i|γ) (если не ноль). Приведенное выше доказательство снова показывает
что это случайное рекурсивное отношение определяет мартингал. есть тонкий
пункт однако: этот мартингейл больше не ограничен, и мартингейл
теорема сходимости не применяется. Однако мы можем полагаться на более простой
инструмент. Определив ln≡logqn, получим для α≠γ
| ln+1(α)=ln(α)+logp(i|α)p(i|γ). | (6) |
с вероятностью p(i|γ) (если не ноль). Таким образом, ln(α)−l0(α)
сумма n независимых одинаково распределенных случайных величин со средним
−S(γ|α)≡∑ip(i|γ)logp(i|α)/p(i|γ).
Помните, что для каждого β набор p(i|β), i∈I, определяет
вероятность на I, а S(γ|α) есть не что иное, как относительная энтропия
p(i|γ) относительно p(i|α), величина, которая всегда
неотрицательны, а на самом деле строго положительны в предположении невырожденности.
Закон больших чисел дает ln(α)∼−nS(γ|α)→−∞, так что qn(α) экспоненциально сходится к 0
со скоростью S(γ|α). Следовательно, как только один из компонентов, скажем
q(γ), стал достаточно близким к единице, с высокой вероятностью состояние
системы будет сходиться к |γ⟩. В этой ситуации каждый
измерение на зонде приводит к получению информации о состоянии системы, которая
в среднем дается для каждой компоненты α≠γ относительной энтропией S(γ|α).
По усиленному закону больших чисел предыдущее обсуждение также подразумевает, что если предельное состояние равно |γ⟩, частота измерений, ведущих к тестовому состоянию |i⟩, будет сходиться к p(i|γ). По гипотезе невырожденности это однозначно фиксирует предельное состояние указателя. Это доказывает утверждение iii). На практике гистограмма всех ni/n, доля зондов, измеренных в состоянии |i⟩ в одной серии из большого числа n повторных измерений, для i∈I, будет близка к p(i|γ) для единственное |γ⟩, позволяющее идентифицировать |γ⟩. Тогда проведение множества независимых однородных серий (начиная каждый эксперимент с одного и того же состояния системы) позволяет восстановить вероятности q0. Следовательно, однородная схема повторных измерений полностью эквивалентна идеальному измерению фон Неймана.
Чтобы закончить обсуждение,
заметим, что по мартингальному свойству, зная результаты зондовых измерений
до момента n0 вероятность оказаться в состоянии указателя |γ⟩ равна
точно qn0(γ), что близко к 1. Величина
1−qn0(γ) — вероятность окончания в другом состоянии указателя. Это
также является порядком величины вероятности того, что приведенное выше обсуждение
ломается. Это происходит именно тогда, когда случайная эволюция делает недействительным линейное приближение.
Если это произойдет, то, скорее всего, это произойдет вскоре после n0, потому что, если
длительное время после n0 qn(α) остаются малыми, закон больших
означает, что они, скорее всего, будут уменьшаться экспоненциально, так что
выход из состояния указателя |γ⟩ будет становиться все труднее и труднее. Брать
некоторое ε>0 такое, что если 1−ε
Наконец, подчеркнем, что (бесконечную) серию косвенных экспериментов можно рассматривать как построение измерительного прибора mb_prep . Действительно, считывание асимптотики частот результатов зондовых измерений позволяет зафиксировать предельное состояние указателя.
Благодарности: Мы благодарим Эльзу Бернар за острые содержательные обсуждения. Эта работа была частично поддержана контрактом ANR ANR-2010-BLANC-0414. Мы благодарим рецензента за полезные комментарии и за указание интересных рефов. Адлер .
- (1) Электронная почта:
- (2) Член CNRS. Электронная почта:
- (3) CEA/DSM/IPhT, Ассоциация научных исследований CNRS
- (4) Дж.А. Уиллер и У.Х. Зурек (ред.) Квантовая теория и измерения, Принстонский ун-т. Пресса (1983).
- (5)
К.С. Торн и др., Phys. Преподобный Летт. 40 (1978) 667;
WG Unruh, Phys. Ред. D18 (1978) 1764;
П. Гранжье, Дж.А. Левенсон и Дж. П. Пойза, Nature 396 (1998) 537.
- (6) Х.П. Брейер и Ф. Петруччионе, Теория открытых квантовых систем, Oxford University Press, 2006; С. Гарош и Дж. М. Раймонд, Изучение квантов: атомы, полости и фотоны, Оксфордский унив. Пресс, 2006.
- (7) Э.Б. Дэвис, Квантовая теория открытых систем, Academics London, 1976.
- (8) К. Хепп, Helv. физ. Акта 45 (1972) 237.
- (9)
Н. Гисин, Phys. Преподобный Летт. 52 (1984) 1657;
L. Diosi, J. Phys. А21 (1988) 2885. - (10) J. Dalibard, Y. Castin and K. Molner, Phys. Преподобный Летт. 68 (1992) 580; и препринт 1992 г. [ArXiv:0805.4002].
- (11) Х. Дж. Чармайкл, Открытый системный подход к квантовой оптике, Лекция. Примечания физ. том 18 (1993), Springer-Berlin.
- (12) Р.Л. Хадсон и К.Р. Партасарати, общ. Мат. физ. 93 (1984) 301.
- (13)
C.W.Gardiner and M.J.Collett, Phys. ред. А31 (1985) 3761;
В.П. Белавкин, коммун. Мат. физ. 146 (1992) 611;
А. Баркиелли, Phys. ред. А34 (1986) 1642; А. Баркиелли и В. П. Белавкин, J. Phys. А24 (1991) 1495.
- (14) Х.М. Уайзман, физ. Ред. A49 (1994) 213
- (15) C. Герлин и др., Nature 448 (2007) 889.
- (16) М. Саффман, Т.Г. Уокер и К. Мольнер, Rev. Mod. физ. 82 (2010) 2313. 9nphσz) с матрицей Паули σz.
- (21) М. Бауэр и Д. Бернар в процессе подготовки.
- (22) С.Л. Adler et al., J. Phys. А34 (2001) 8795; Р. ван Гендель, Дж.К. Stockton and H. Mabuchi, IEEE T. Automat. контр. 50 (2005) 768 и Phys. Ред. A70 (2004 г.) 022106.
- (23) В рамках гипотез (например, слабой связи) можно утверждать, что дискретная установка, которую мы рассматриваем, допускает непрерывные во времени пределы, совпадающие с моделями Гизина-Диози; ГББ .
- (24)
Пункт iii), кажется, не был рассмотрен в Adler , которые только доказывают коллапс, не объясняя, как идентифицировать предельное состояние указателя в данной реализации. Пункт iv) показывает, что скорость сходимости зависит от предельного состояния указателя, что противоречит обычным оценкам Адлера .